- 思维导图
- BackBone
- 其他经典网络
- 实例分割
- 目标检测与识别
- 网络中的各种细节
- 项目相关
- 竞赛相关
- 智力题
CV方向知识点汇总
思维导图
BackBone
AlexNet(2012)

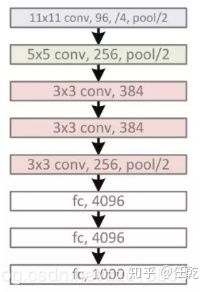
网络的输入是227×227×3(论文中为224×224×3,但由于是通过裁剪,不然直接裁剪为227×227×3,免去后续的补边,Caffe也是如此修改的)的图像,网络一共有八层,其中前五个是卷基层,后3个是全连接层。
可能由于当时GPU连接间的处理限制, AlexNet使用两个单独的GPU在 ImageNet数据库上执行训练,因此常常能看到将其拆分为两个网络的结构示意图,每一部分的kernel数量为实际kernel数量的一半。第二,第四和第五个卷积层的内核仅与上一层存放在同一GPU上的内核映射相连。第三个卷积层的内核连接到第二层中的所有内核映射。全连接层中的神经元连接到前一层中的所有神经元。
Conv1阶段:
卷积:
输入:227×227×3,卷积核:11×11×3,卷积核个数:96,步长:4,输出:55×55×96
激活函数:ReLU
归一化:LRN(局部响应归一化层,Local Response Normalization Layer),local_size=5
池化:
类型:max pooling,池化窗口:3×3,步长:2,输出:27×27×96
Conv2阶段:
卷积:
输入:27×27×96,卷积核:5×5×96,卷积核个数:256,步长:1,padding:same(相同补白,此处为2×2,使得卷积后图像大小不变),输出:27×27×256
激活函数:ReLU
归一化:LRN,local_size=5
池化:
类型:max pooling,池化窗口:3×3,步长:2,输出:13×13×256
Conv3阶段:
卷积:
输入:13×13×256,卷积核:3×3×256,卷积核个数:384,步长:1,padding:same(1×1),输出:13×13×384
激活函数:ReLU
Conv4阶段:
卷积:
输入:13×13×384,卷积核:3×3×384,卷积核个数:384,步长:1,padding:same(1×1),输出:13×13×384
激活函数:ReLU
Conv5阶段:
卷积:
输入:13×13×384,卷积核:3×3×384,卷积核个数:256,步长:1,padding:same(1×1),输出:13×13×256
激活函数:ReLU
池化:
类型:max pooling,池化窗口:3×3,步长:2,输出:6×6×256
FC6阶段:
输入:6×6×256,flatten:[-1,9216],输出:4096
激活函数:ReLU
Dropout:0.5
一说:
第6层采用6*6*256尺寸的滤波器对输入数据进行卷积运算;每个6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6*6*256尺寸的滤波器对输入数据进行卷积,通过4096个神经元的输出运算结果;然后通过ReLU激活函数以及Dropout运算输出4096个本层的输出结果值。
很明显在第6层中,采用的滤波器的尺寸(6*6*256)和待处理的feature map的尺寸(6*6*256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而采用的滤波器的尺寸和待处理的feature map的尺寸不相同,每个滤波器的系数都会与多个feature map中像素相乘。因此第6层被称为全连接层。
但是现在找到的源码基本都是直接将最后一个卷积层的输出降维,作为全连接层的输入,因此这一说法有待考证。
FC7阶段:
输入:4096,输出:4096
激活函数:ReLU
Dropout:0.5
FC8阶段:
输入:4096,输出:1000
损失函数:Softmax-crossentropy
结构上重要的改进:
- 使用ReLU激活函数:ReLU(x)=max(x,0),具体在激活函数部分讲解。
- 0.5概率的Dropout来对抗过拟合,具体在Dropout部分讲解。
- LRN(局部响应归一化层,Local Response Normalization Layer)
LRN模拟神经生物学上一个叫做 侧抑制(lateral inhibitio)的功能,侧抑制指的是被激活的神经元会抑制相邻的神经元。
引入这一层的主要目的,主要是为了防止过拟合,增加模型的泛化能力。
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是tanh和sigmoid这些传统的激活函数的值域都是有范围的(即他们自带归一化功能),但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化。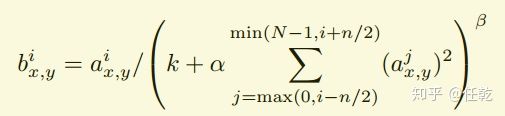 LRN
LRN其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。
k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
具体方法是在某一确定位置(x,y)将前后各2/n个feature map求和作为下一层的输入。但是存在争论,说LRN Layer其实并没有什么效果,在这里不讨论。 - Overlapping Pooling
传统的卷积层中,相邻的池化单元是不重叠的,即步长等于池化窗口的尺寸。AlexNet中由于步长小于池化窗口的尺寸,因此相邻的池化窗口间存在重叠的部分。实验结果显示这样的池化方法相比于传统池化方法对准确率有略微的提升。
VGG(2014)

VGG网络是2014年由牛津大学Visual Geometry Group提出的,是迄今为止最为经典的卷积神经网络,即使到了今天,也常使用其前半部分结构用于特征的提取。他不仅提出了使用基础块代替网络层的思想,使得网络结构看起来更为简单优雅,而且证明了增加网络的深度能够在一定程度上影响网络的最终性能。
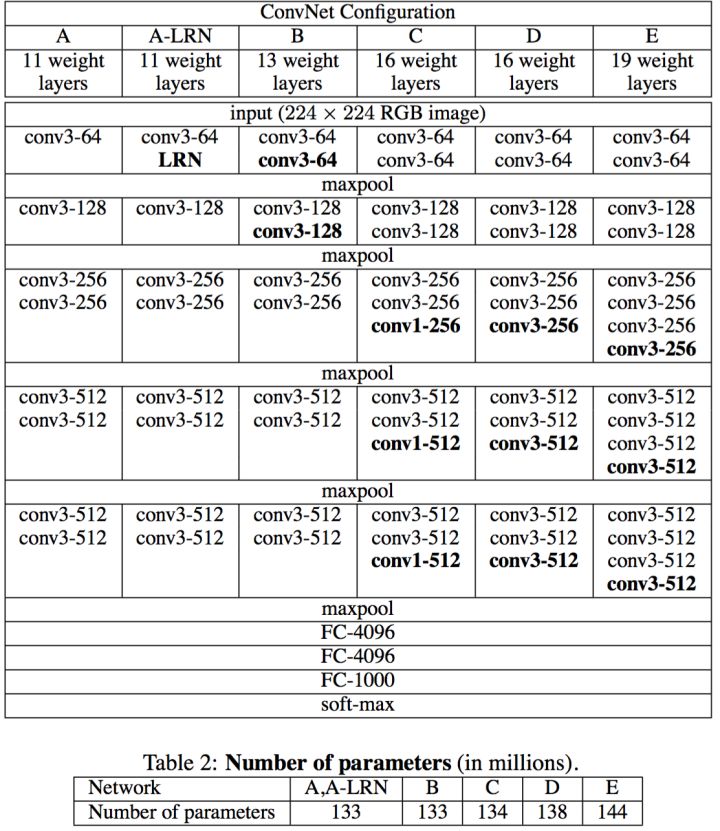
论文中一共提出了6种网络结构,每种结构名称后的数字代表他们具有的网络层数,他们之间的主要差别也就在于此。其中最为重要的是VGG16这一模型,VGG16和VGG19的效果相当,但是VGG16的结构更简洁美观,因此VGG16应用的更为广泛一些。我们就以VGG16为例进行介绍。
VGG16由13个卷积层和3个全连接层(5个池化层不计算在内)组成,其输入为224×224×3的图像。其他的VGG网络也仅在卷积层数量上有所差异,其余结构均相同。
整体上看,VGG还是遵循着input -> n(Conv->ReLU->MaxPool) -> 3fc -> Softmax -> output的结构。
正如前面所说,VGG使用了块代替层的思想,具体的来说,它提出了构建基础的卷积块和全连接块来替代卷积层和全连接层,而这里的块是由多个输出通道相同的层组成。VGG16中的13个卷积层被5个池化层分割为5个卷积块,每个卷积块中输出通道数相同,即使在不同的模型中,同层的卷积块中的输出通道数也相同。
相比于LeNet和AlexNet较为复杂的卷积核、步长设置,VGGNet的卷积块中统一采用的卷积核大小为3×3,步长为1,padding为1,池化窗口大小为2×2,步长为2,padding为0。这种特性使得我们在将网络迁移至其他任务中时(输入网络的图片尺寸可能发生变化),不需要将过多的精力花费在这些超参数的设计上,只需要关注每一层输入输出的通道数即可。
卷积块1
包含2个通道数为64,激活函数为ReLU的卷积层,输入是224×224×3的图像,输出为224×224×64。
池化层1 类型:max pooling,输入为224×224×64,池化窗口:2×2,步长:2×2,输出为112×112×64。
卷积块2 包含2个通道数为128,激活函数为ReLU的卷积层,输入是112×112×64,输出为112×112×128。
最大池化层2 类型:max pooling,输入为112×112×128,池化窗口:2×2,步长:2×2,输出为56×56×128。
卷积块3 包含3个通道数为256,激活函数为ReLU的卷积层,输入是56×56×128,输出为56×56×256。
最大池化层3 类型:max pooling,输入为56×56×256,池化窗口:2×2,步长:2×2,输出为28×28×256。
卷积块4 包含3个通道数为512,激活函数为ReLU的卷积层,输入是28×28×256,输出为28×28×512。
最大池化层4 类型:max pooling,输入为28×28×512,池化窗口:2×2,步长:2×2,输出为14×14×512。
卷积块5 包含3个通道数为512,激活函数为ReLU的卷积层,输入是14×14×512,输出为14×14×512。
最大池化层5 类型:max pooling,输入为14×14×512,池化窗口:2×2,步长:2×2,输出为7×7×512。
全连接层1
输入:7×7×512 -> 25088,输出:4096,激活函数:ReLU
全连接层2
输入:4096,输出:4096,激活函数:ReLU
全连接层3
输入:4096,输出:1000,激活函数:Softmax
卷积层的堆叠作用
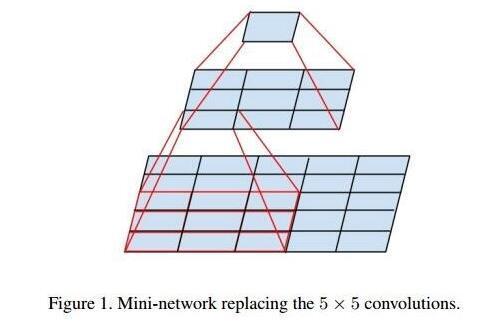
直观上我们会觉得大的卷积核更好,因为它可以提取到更大区域内的信息。但是实际上,大卷积核可以用多个小卷积核进行代替。例如,一个5×5的卷积核就可以用两个串联的3×3卷积核来代替,一个7×7的卷积核就可以用三个串联的3×3卷积核来代替。这样的替代方式有两点好处:
-
减少了参数个数:
假设输入与输出的channel数都为C。
两个串联的小卷积核需要3×3×C×C×2=18C^2个参数,一个5×5的卷积核则有25C^2个参数。
三个串联的小卷积核需要3×3×C×C×3=27C^2个参数,一个7×7的卷积核则有49C^2个参数。
通过小卷积核的堆叠实现与大卷积核相同的感受野,从而大大减少了参数的数量。(升维与降维的情况下呢?) -
引入了更多的非线性:
多少个串联的小卷积核就对应着多少次激活(activation)的过程,而一个大的卷积核就只有一次激活的过程。引入了更多的非线性变换,也就意味着模型的表达能力会更强,可以去拟合更高维的分布。
值得一提的是,VGGNet结构C里还用到了1×1的卷积核。但是这里对这种卷积核的使用并不是像Inception里面拿来对通道进行整合,模拟升维和降维,这里并没有改变通道数,所以可以理解为是进一步的引入非线性。
总地来说,VGGNet的出现让我们知道CNN的潜力无穷,并且越深的网络在分类问题上表现出来的性能越好,并不是越大的卷积核就越好,也不是越小的就越好,就VGGNet来看, 3x3卷积核是最合理的。
作者对照实验组说明

-
A和A-LRN对比:分析LRN在网络中的效果
A和A-LRN对比:精度提高0.1%,可以认为精度变化不大,但是LRN操作会增大计算量,所以作者认为在网络中添加LRN意义不大。 -
A和B对比:分析在网络靠近输入部分增加卷积层数的效果
A和B对比:top-1提高0.9%,说明在靠近输入部分增加深度可以提高精度。 -
B和C对比:分析在网络靠近输出部分增加卷积层数的效果
B和C对比:top-1提高0.6%,说明在靠近输出部分增加深度也可以提高精度。 -
C和D对比:分析1X1卷积核和3X3卷积核的对比效果
C和D对比:top-1提高1.1%,说明3X3卷积核的效果要明显由于1X1卷积核的效果。 -
D和E对比:分析在网络靠近输出部分增加卷积层数的效果(这个和3)的作用有点像,只是网络进一步加深)
D和E对比:top-1反而下降0.3%,说明深度增加到一定程度后,精度不再明显提升。 -
总结论:
网络深度增加可以提高精度,但是增加到一定程度之后就不适合再增加,增加3X3的卷积核比1X1的效果好。
multi-crop(多裁剪评估)和dense evaluation(密集评估)
作者在论文中提出了一种策略,即使用卷积层代替全连接层(具体理解可参考FCN网络),这种策略不限制输入图片的大小,最终输出结果是一个w×h×n的score map。其中,w和h与输入图片大小有关,而n为类别数。而将w×h个值进行sum pool(对每一个channel进行求和),即可得到在某一类上的概率。这种方法叫做dense evaluation。
另一种策略就是经常使用的卷积层+全连接层。通过将测试图片缩放到不同大小Q,Q可以不等于S(训练时图片大小)。在Q×Q图片上裁剪出多个S×S的图像块,将这些图像块进行测试,得到多个1×n维的向量。通过对这些向量每一纬求平均,得到一个1×n维的向量,从而得到在某一类上的概率。这种方法叫做multi-crop。
作者认为,这两种方法的差别在于convolution boundary condition不同:dense由于不限制图片大小,可以利用像素点及其周围像素的信息(来自于卷积和池化),包含了一些上下文信息,增大了感受野,因此提高分类的准确度;而multi-crop由于从图片上裁剪再输网络,需要对图像进行padding,因此增加了噪声(个人理解应为裁剪的区域不同,相当于训练或检测的样本不同,等于引入了噪声)。但是由于multi-crop需要裁剪出大量图片,每张图片都要单独计算,增加了计算量,并且准确率提升不大,multi-crop比dense在top-1错误率上提升只有0.2。
此概念首先在NIN(Network In Network)中提出。全局池化(global pooling)指滑动窗口的大小与整个feature map的大小一样,这样一整张feature map只产生一个值。比如一个4×4的feature map使用传统的池化方法(2×2,2s),那么最终产生的feature map大小为2×2。而如果使用全局池化的话(4×4,1s,即大小与feature map相同),一个feature map只产生一个值,即输出为1×1。如果前一层有多个feature map的话,只需要把经过全局池化的结果堆叠起来即可。如果使用Average池化方法,那么就成为Global Average Pooling,即GAP。
从而可以总结出,如果输入feature map为W×H×C,那么经过全局池化之后的输出就为1×1×C。
通常在最后一层卷积层中将输出的feature map数设置与类别数相同,可使用GAP对每个feature map求全图均值,通过Softmax得到每个类别的概率,这样做等效于卷积层后直接添加Softmax层。即GAP在减少参数量的同时,强行引导网络把最后的feature map学习成对应类别的confidence map。如果需要替代多个全连接层,就将多个1×1卷积的卷积核数量设置为对应全连接的单元数。

GoogLeNet(Inception v1,2014)
要理解GoogLeNet,首先需要先了解NIN(Network In Network)提出的MLPConv结构和通过GAP替代全连接层减少参数量的思想。
MLPConv这一结构使用了小的多层全连接网络替换掉卷积操作。但在实际上,是通过几个1×1卷积实现的,这是因为全连接层能够转化为卷积层,通过1×1卷积核实现了不同feature map间的信息交流。
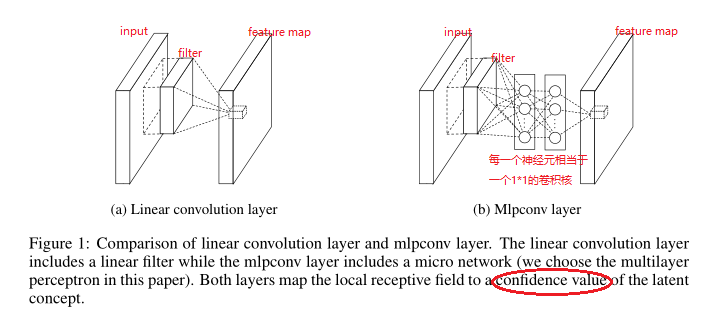
CNN提取特征一般经过卷积/池化/激活三个步骤。其中,CNN卷积filter是一种广义线性模型(GLM),仅仅是将输入(局部感受野中的元素)进行线性组合,因此其抽象能力是比较低的。所提取的特征高度非线性时,我们需要更加多的filters来提取各种潜在的特征,但filters太多,导致网络参数太多,网络过于复杂,计算压力太大。为了提取更抽象的深层特征,提出用多层感知机(Muti-layer perception)对输入(局部感受野中的元素)进行更加复杂的运算,提高抽象表达能力。
MLPConv层实际上是Conv+MLP(多层感知器),因为Conv是线性的,而MLP是非线性的,后者能够得到更高的抽象,泛化能力更强。
在跨通道(cross channel,cross feature map)情况下,MLPConv等价于卷积层+1×1卷积层×2,所以此时MLPConv层也叫CCCP层(Cascaded Cross Channel Parametric Pooling)。
关于GAP替代全连接层,可以参考VGG中全连接层->全局平均池化层(GAP)部分。通过这样的操作,使得原来占有总参数量中极大比例的全连接层被池化层替代,同时降低了过拟合的风险。
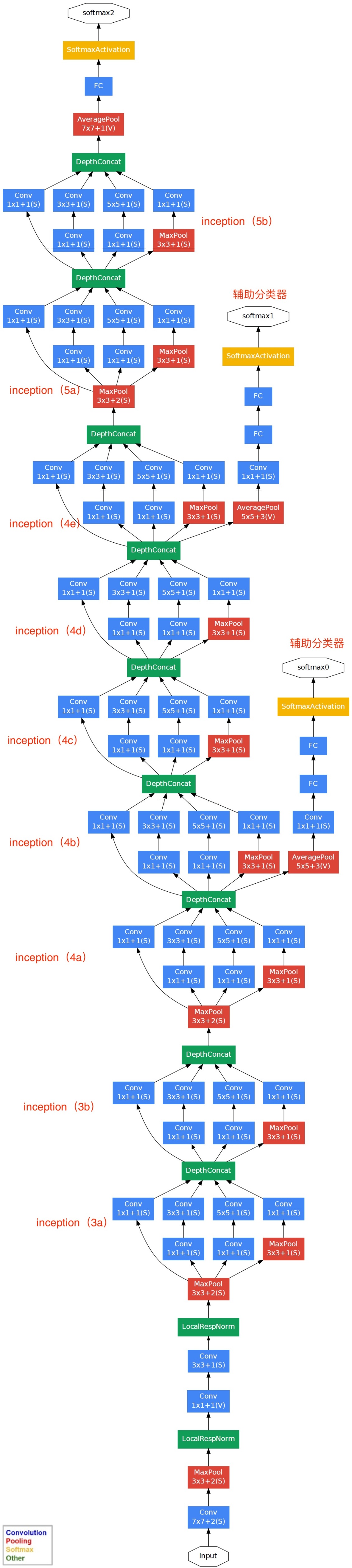
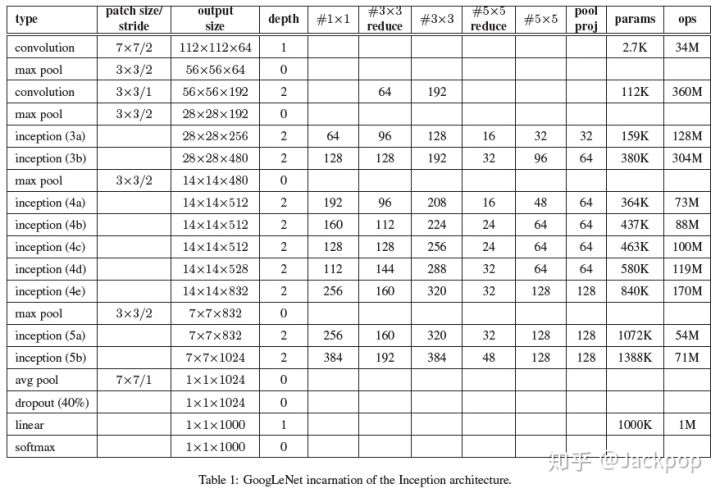
与VGG网络相同,GoogLeNet也使用了基础块的思想,它引入了Inception块替代一般的卷积层,主要通过增加网络的宽度和深度提高整个网络的精度。同时借助了NIN的思想,将全连接层变为了GAP+1×1卷积层,减少量全连接层带来的参数量过多、容易过拟合的问题。
GoogLeNet是一个输入为224×224×3图像的具有22层含有参数的网络(算上没有参数的pooling层则有27层),以池化层为分界,可以将整个网络结构分为5个模块。
模块1
卷积层1:输入:224×224×3,卷积核:7×7,卷积核个数:64,步长:2,padding:same,激活函数:ReLU,输出:112×112×64
池化层1:类型:max pooling,输入:112×112×64,池化窗口:3×3,步长:2,padding:same,输出:56×56×64
模块2
卷积层2_3x3_reduce:输入:56×56×64,卷积核:1×1,卷积核个数:64,步长:1,padding:valid,激活函数:ReLU,输出:56×56×64
卷积层2_3x3:输入:56×56×64,卷积核:3×3,卷积核个数:192,步长:1,padding:same,激活函数:ReLU,输出:56×56×192
池化层2:类型:max pooling,输入:56×56×192,池化窗口:3×3,步长:2,padding:same,输出:28×28×192
模块3_a
线路1
卷积层3a_1×1:输入28×28×192,卷积核:1×1,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:28×28×64
线路2
卷积层3a_3x3_reduce:输入28×28×192,卷积核:1×1,卷积核个数:96,步长:1,padding:same,激活函数:ReLU,输出:28×28×96
卷积层3a_3x3:输入28×28×96,卷积核:3×3,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:28×28×128
线路3
卷积层3a_5x5_reduce:输入28×28×192,卷积核:1×1,卷积核个数:16,步长:1,padding:same,激活函数:ReLU,输出:28×28×16
卷积层3a_5x5:输入28×28×96,卷积核:5×5,卷积核个数:32,步长:1,padding:same,激活函数:ReLU,输出:28×28×32
路线4
池化层3a_pool:类型:max pooling,输入28×28×192,池化窗口:3×3,步长:1,padding:same,输出:28×28×192
卷积层3a_pool_proj:输入28×28×192,卷积核:1×1,卷积核个数:32,步长:1,padding:same,激活函数:ReLU,输出:28×28×32
合并层:输出:28×28×64+128+32+32=28×28×256
模块3_b
线路1
卷积层3b_1×1:输入28×28×256,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:28×28×128
线路2
卷积层3b_3x3_reduce:输入28×28×256,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:28×28×128
卷积层3b_3x3:输入28×28×128,卷积核:3×3,卷积核个数:192,步长:1,padding:same,激活函数:ReLU,输出:28×28×192
线路3
卷积层3b_5x5_reduce:输入28×28×256,卷积核:1×1,卷积核个数:32,步长:1,padding:same,激活函数:ReLU,输出:28×28×32
卷积层3b_5x5:输入28×28×32,卷积核:5×5,卷积核个数:96,步长:1,padding:same,激活函数:ReLU,输出:28×28×96
线路4
池化层3b_pool:类型:max pooling,输入28×28×256,池化窗口:3×3,步长:1,padding:same,输出:28×28×256
卷积层3b_pool_proj:输入28×28×256,卷积核:1×1,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:28×28×64
合并层:输出:28×28×128+192+96+64=28×28×480
池化层3:类型:max pooling,输入:28×28×480,池化窗口:3×3,步长:2,padding:same,输出:14×14×480
模块4_a
线路1
卷积层4a_1x1:输入14×14×480,卷积核:1×1,卷积核个数:192,步长:1,padding:same,激活函数:ReLU,输出:14×14×192
线路2
卷积层4a_3x3_reduce:输入14×14×480,卷积核:1×1,卷积核个数:96,步长:1,padding:same,激活函数:ReLU,输出:14×14×96
卷积层4a_3x3:输入14×14×96,卷积核:3×3,卷积核个数:208,步长:1,padding:same,激活函数:ReLU,输出:14×14×208
线路3
卷积层4a_5x5_reduce:输入14×14×480,卷积核:1×1,卷积核个数:16,步长:1,padding:same,激活函数:ReLU,输出:14×14×16
卷积层4a_5x5:输入14×14×16,卷积核:5×5,卷积核个数:48,步长:1,padding:same,激活函数:ReLU,输出:14×14×48
路线4
池化层4a_pool:类型:max pooling,输入14×14×480,池化窗口:3×3,步长:1,padding:same,输出:14×14×480
卷积层4a_pool_proj:输入14×14×480,卷积核:1×1,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
合并层:输出:14×14×192+208+48+64=14×14×512
模块4_b
线路1
卷积层4b_1×1:输入14×14×512,卷积核:1×1,卷积核个数:160,步长:1,padding:same,激活函数:ReLU,输出:14×14×160
线路2
卷积层4b_3x3_reduce:输入14×14×512,卷积核:1×1,卷积核个数:112,步长:1,padding:same,激活函数:ReLU,输出:14×14×112
卷积层4b_3x3:输入14×14×112,卷积核:3×3,卷积核个数:224,步长:1,padding:same,激活函数:ReLU,输出:14×14×224
线路3
卷积层4b_5x5_reduce:输入14×14×512,卷积核:1×1,卷积核个数:24,步长:1,padding:same,激活函数:ReLU,输出:14×14×24
卷积层4b_5x5:输入14×14×24,卷积核:5×5,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
线路4
池化层4b_pool:类型:max pooling,输入14×14×512,池化窗口:3×3,步长:1,padding:same,输出:14×14×512
卷积层4b_pool_proj:输入14×14×512,卷积核:1×1,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
合并层:输出:14×14×160+224+64+64=14×14×512
模块4_c
线路1
卷积层4c_1×1:输入14×14×512,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:14×14×128
线路2
卷积层4c_3x3_reduce:输入14×14×512,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:14×14×128
卷积层4c_3x3:输入14×14×128,卷积核:3×3,卷积核个数:256,步长:1,padding:same,激活函数:ReLU,输出:14×14×256
线路3
卷积层4c_5x5_reduce:输入14×14×512,卷积核:1×1,卷积核个数:24,步长:1,padding:same,激活函数:ReLU,输出:14×14×24
卷积层4c_5x5:输入14×14×24,卷积核:5×5,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
线路4
池化层4c_pool:类型:max pooling,输入14×14×512,池化窗口:3×3,步长:1,padding:same,输出:14×14×512
卷积层4c_pool_proj:输入14×14×512,卷积核:1×1,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
合并层:输出:14×14×128+256+64+64=14×14×512
模块4_d
线路1
卷积层4d_1×1:输入14×14×512,卷积核:1×1,卷积核个数:112,步长:1,padding:same,激活函数:ReLU,输出:14×14×112
线路2
卷积层4d_3x3_reduce:输入14×14×512,卷积核:1×1,卷积核个数:144,步长:1,padding:same,激活函数:ReLU,输出:14×14×144
卷积层4d_3x3:输入14×14×144,卷积核:3×3,卷积核个数:288,步长:1,padding:same,激活函数:ReLU,输出:14×14×288
线路3
卷积层4d_5x5_reduce:输入14×14×512,卷积核:1×1,卷积核个数:32,步长:1,padding:same,激活函数:ReLU,输出:14×14×32
卷积层4d_5x5:输入14×14×32,卷积核:5×5,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
线路4
池化层4d_pool:类型:max pooling,输入14×14×512,池化窗口:3×3,步长:1,padding:same,输出:14×14×512
卷积层4d_pool_proj:输入14×14×512,卷积核:1×1,卷积核个数:64,步长:1,padding:same,激活函数:ReLU,输出:14×14×64
合并层:输出:14×14×112+288+64+64=14×14×528
模块4_e
线路1
卷积层4e_1×1:输入14×14×512,卷积核:1×1,卷积核个数:256,步长:1,padding:same,激活函数:ReLU,输出:14×14×256
线路2
卷积层4e_3x3_reduce:输入14×14×512,卷积核:1×1,卷积核个数:160,步长:1,padding:same,激活函数:ReLU,输出:14×14×160
卷积层4e_3x3:输入14×14×160,卷积核:3×3,卷积核个数:320,步长:1,padding:same,激活函数:ReLU,输出:14×14×320
线路3
卷积层4e_5x5_reduce:输入14×14×512,卷积核:1×1,卷积核个数:32,步长:1,padding:same,激活函数:ReLU,输出:14×14×32
卷积层4e_5x5:输入14×14×32,卷积核:5×5,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:14×14×128
线路4
池化层4e_pool:类型:max pooling,输入14×14×512,池化窗口:3×3,步长:1,padding:same,输出:14×14×512
卷积层4e_pool_proj:输入14×14×512,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:14×14×128
合并层:输出:14×14×256+320+128+128=14×14×832
池化层4:类型:max pooling,输入:14×14×832,池化窗口:3×3,步长:2,padding:same,输出:7×7×832
模块5_a
线路1
卷积层5a_1x1:输入7×7×832,卷积核:1×1,卷积核个数:256,步长:1,padding:same,激活函数:ReLU,输出:7×7×256
线路2
卷积层5a_3x3_reduce:输入7×7×832,卷积核:1×1,卷积核个数:160,步长:1,padding:same,激活函数:ReLU,输出:7×7×160
卷积层5a_3x3:输入7×7×160,卷积核:3×3,卷积核个数:320,步长:1,padding:same,激活函数:ReLU,输出:7×7×320
线路3
卷积层5a_5x5_reduce:输入7×7×832,卷积核:1×1,卷积核个数:32,步长:1,padding:same,激活函数:ReLU,输出:7×7×32
卷积层5a_5x5:输入7×7×32,卷积核:5×5,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:7×7×128
路线4
池化层5a_pool:类型:max pooling,输入7×7×832,池化窗口:3×3,步长:1,padding:same,输出:7×7×832
卷积层5a_pool_proj:输入7×7×832,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:7×7×128
合并层:输出:7×7×256+320+128+128=7×7×832
模块5_b
线路1
卷积层5b_1x1:输入7×7×832,卷积核:1×1,卷积核个数:384,步长:1,padding:same,激活函数:ReLU,输出:7×7×384
线路2
卷积层5b_3x3_reduce:输入7×7×832,卷积核:1×1,卷积核个数:192,步长:1,padding:same,激活函数:ReLU,输出:7×7×192
卷积层5b_3x3:输入7×7×192,卷积核:3×3,卷积核个数:384,步长:1,padding:same,激活函数:ReLU,输出:7×7×384
线路3
卷积层5b_5x5_reduce:输入7×7×832,卷积核:1×1,卷积核个数:48,步长:1,padding:same,激活函数:ReLU,输出:7×7×48
卷积层5b_5x5:输入7×7×48,卷积核:5×5,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:7×7×128
路线4
池化层5b_pool:类型:max pooling,输入7×7×832,池化窗口:3×3,步长:1,padding:same,输出:7×7×832
卷积层5b_pool_proj:输入7×7×832,卷积核:1×1,卷积核个数:128,步长:1,padding:same,激活函数:ReLU,输出:7×7×128
合并层:输出:7×7×384+384+128+128=7×7×1024
池化层5:类型:avg pooling,输入:7×7×1024,池化窗口:7×7,步长:1,padding:valid,输出:1×1×1024
全连接层1:输入:1024,输出:1000,dropout:40%,激活函数:Softmax
对于GoogLeNet而言,重点是名为Inception块的结构。
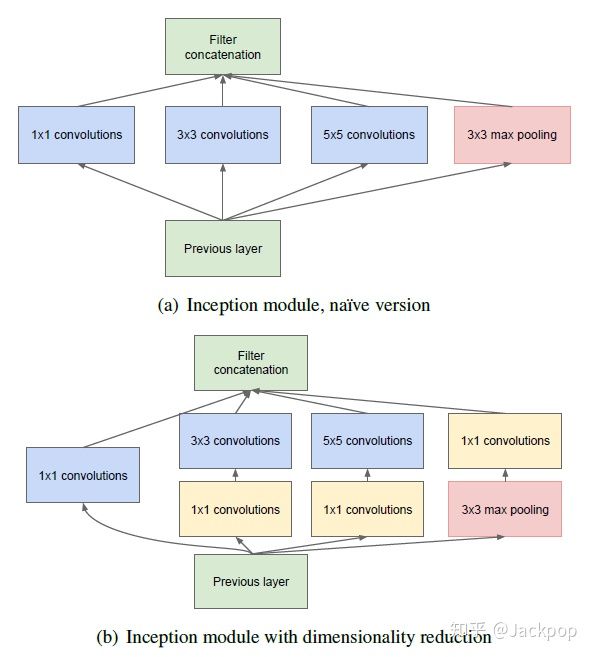
上图为Inception的结构,分布为简化版和降维版。两者的主要区别在于降维版在第2-4条线路上增加了1×1卷积来减少通道维度,以减小模型复杂度。
Inception包含4条并行线路,其中,第1、2、3条线路分别采用了1×1、3×3、5×5,不同的卷积核大小来对输入图像进行特征提取,使用不同大小卷积核能够充分提取图像特征。其中,第2、3两条线路都加入了1×1的卷积层,这两条线路的1×1与第1条线路1×1的卷积层的功能不同,第1条线路是用于特征提取,而第2、3条线路的目的是降低模型复杂度。第4条线路采用的不是卷积层,而是3×3的池化层,之后再加上1×1的卷积层。注意,第4条线路1×1卷积层的位置与第2、3条线路有所区别。
为什么在第4条线路上先进行池化,之后再进行1×1卷积呢?我的理解是由于池化后,虽然特征图的尺寸和深度没有发生变化,但是特征图包含是信息量实际上是减少的(max pooling的下采样作用)。之后连接的1×1卷积,一方面实现了降维,以免该Inception块输出的维度过大,另一方面是为了将不同特征图在同一像素上的信息进行合并,重新将被max pooling去除掉的细节部分还原回来。
最后,这4条线路的输出保持相同的尺寸,经过Filter Concatenation在维度上进行拼接,得到Inception块的输出。
值得注意的是,网络中有三个softmax,这是为了减轻在深层网络反向传播时梯度消失的影响,也就是说,整个网络的loss是由三个softmax共同组成的,这样在反向传播的时候,即使最后一个softmax传播回来的梯度消失了,还有前两个softmax传播回来的梯度进行辅助,通过两个辅助 softmax 分类器向模型低层次注入梯度,同时也提供了额外的正则化,也让底层网络提取的特征更具判别性。文中也提到这两个辅助 softmax 分类器的损失函数在计算总的损失是需要添加一个衰减系数,文中给出的是0.3。在对网络进行测试的时候,这两个额外的softmax将会被拿掉。这样不仅仅减轻了梯度消失的影响,而且加速了网络的收敛。
Inception
Xception
SqueezeNet
ShuffleNet
ResNet(2015)
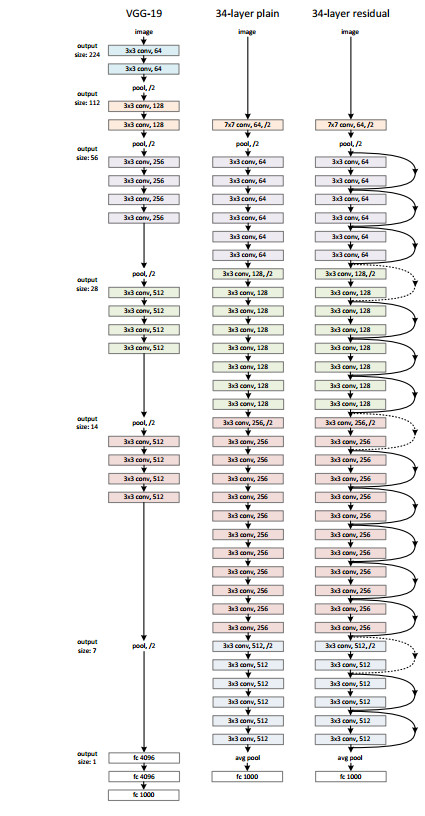
ResNet 将深度学习推到了新的高度,因为它首次将错误率降到比人类还低的水平,网络深度甚至达到1202层,所以它具有里程碑式的意义。文章中作者提出了多种不同深度的结构,其中50,101和152层的网络后来用的比较多。其设计理念是基于VGG的风格(3×3卷积+下采样/2的同时卷积核数量×2),保持简洁并通过增加网络的深度提高网络的性能。
什么叫残差:
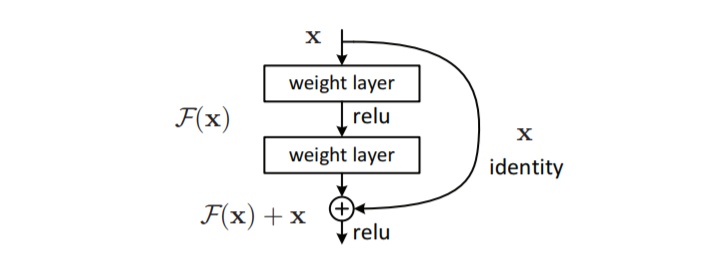
残差在数理统计中的定义是观测值与估计值之间的差值,但这和残差网络中的定义不同。
假如我们有一个输入x,并且希望通过网络得到他的映射H(x)。如果我们将残差定义为F(x)=H(x)-x,那么理想的映射值应该为H(x)=F(x)+x。如果引入到残差网络的残差单元结构中,可以发现由于得到该单元的输出之前,将通过两个权重层的输出结果和输入x进行了相加,即这个残差单元的输出为H(x)=F(x)+x。也就是说,实际通过两层权重层直接输出得到的是残差F(x),两层权重层学习到的参数是x映射到残差F(x)的参数,不是直接学习x映射到H(x)的参数。
残差单元中输入与两层权重层输出的连线称作shortcut connection。根据ResNet的结构图可以看到,shortcut有虚线和实线的区分。虚线的地方由于weight layers使用了stride为2的卷积,因此input和output的尺寸是不同的,没法直接进行element wise addition(size,kernel channel相同,即两个tensor相同位置上的元素相加后得到新的tensor),实际上需要通过stride为2(input_size/residual_size)的1×1卷积对input进行处理,才能进行element wise addition。
由于残差结构的特殊性,由loss对输入求导时,导数项将被分解为两个,其中一个直接对输入求导的导数项不会消失,所以梯度一直存在。
创新点:
- 加入shortcut connection解决梯度消失的问题(有说法并没有解决梯度消失的问题,He kaiming的论文中也说了:臭名昭著的梯度弥散/爆炸问题已经很大程度上被normalized initialization and intermediate normalization layers解决了;残差网络使信息更容易在各层之间流动,包括在前向传播时提供特征重用,在反向传播时缓解梯度信号消失,原作者在一篇后续文章中给出了讨论),以使得更深的网络能比较浅的网络获得更优的精度。
- ResNet的kernel channel比VGG19少(个人理解为同尺寸输出时对应的kernel channel),且FC层被Ave Pooling替代(GoogLeNet),同时只在开头和末尾的位置有pooling层,中间的下采样通过stride为2的卷积操作实现。
为什么work?
- 从前后向信息传播的角度来看
何凯明在后续论文中对残差网络为什么能work给出了一种解释,由于残差结构的存在,在前向传播中,输入信号能够从任意低层直接传播到高层,由于包含了一个天然的恒等映射,一定程度上可以解决网络退化的问题。在反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度消失的问题。总的来说可以认为残差连接使得信息的前后向传播更加顺畅。
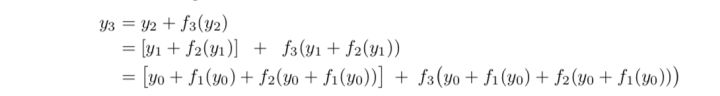
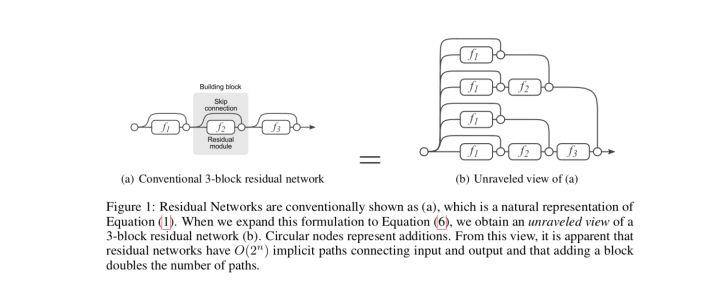
- 集成学习的角度
将残差网络展开,以一个三层的ResNet为例,可以得到如上的树形结构:
这样残差网络可以被看作是一系列路径集合组成的一个集成模型,其中不同的路径包含了不同的网络层子集。经过实验,去除掉残差网络的部分网络层,或交换某些网络模块的顺序(改变网络的结构,丢弃一部分路径的同时引入新路径),发现网络的表现与正确网络路径数平滑相关(路径变化时网络表现没有剧烈变化)。这表明残差网络展开后的路径具有一定的独立性和冗余性,使得残差网络表现得像一个集成模型。
作者还通过实验表明,残差网络中主要在训练中贡献了梯度的是那些相对较短的路径。这与1.中的观点有所区别,残差网络并不是通过保留整个网络深度上的梯度流动来抑制梯度消失的问题,但实际上这些较短路径正是由残差结构引入的。
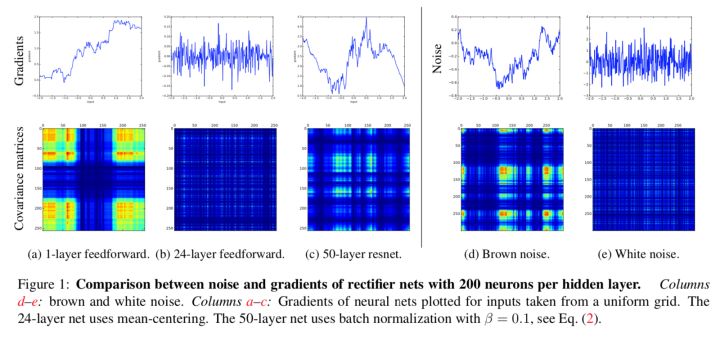
- 梯度破碎问题
2018年时,有人提出了一个新的观点,残差网络解决的问题并非梯度消失和网络退化问题,而是梯度破碎问题。什么是梯度破碎问题呢?大致是说,一张图片是具有局部相关性的,那么梯度也应该类似的具有局部相关性,这样更新的权重才有意义,梯度破碎就是梯度的局部相关性(空间结构)被破坏。但是在标准的前馈神经网络中,随着深度增加,梯度将从棕色噪声逐渐变为白噪声(从有规律的变化为无规律的),神经元梯度的相关性按指数级减少($\frac{1}{2^L}$),同时梯度的空间结构也随着深度增加被逐渐消除。而在残差网络中,神经元梯度相关性的减少速度从指数级下降到亚线性级($\frac{1}{\sqrt(L)}$),神经元梯度介于棕色噪声与白噪声之间,梯度的空间结构被极大地保留下来。
残差单元结构改进:
He Kaiming在后续论文中提出了原始残差单元结构的改进,如下图。
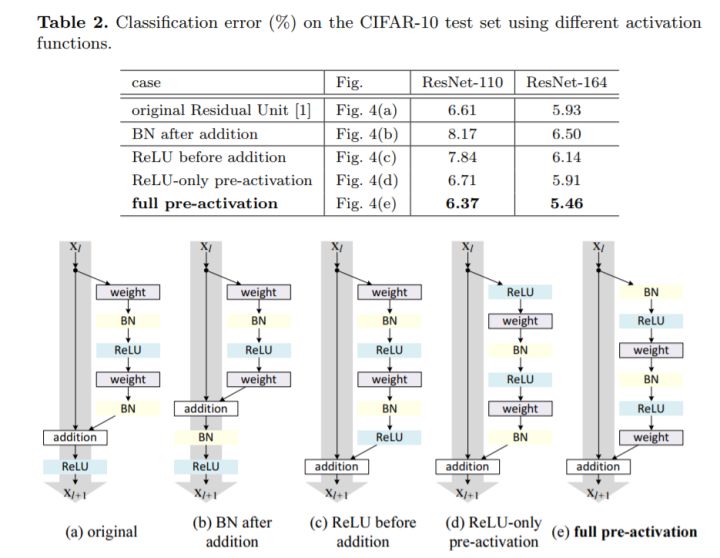
常用的ResNet结构一览:

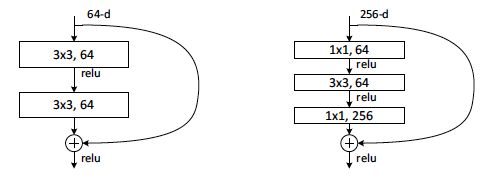
在ResNet-50/101/152的结构中使用增加了BottleNeck结构的残差单元,将原本2层网络堆叠变为了3层。使用BottleNeck结构的目的是为了降维,以减少3×3卷积的参数量。
Input层的7×7卷积?
尽可能保留原始图像的信息, 而不需要增加channels数。
多channels的非线性激活层是非常昂贵的, 在input layer用big kernel换多channels是划算的,第一层卷积可以非常大而不会大幅增加实际的权重数。如果你想在某个地方进行大卷积,第一层通常是唯一的选择。
个人的理解还是在于减少计算量和参数量,对于7×7卷积核,计算量(输入channel数 × 卷积核_w × 卷积核_h × 输出_w × 输出_h × 输出channel数):
7×7×3×112×112×64=118013952≈118M
参数量((卷积核_w × 卷积核_h × 输入channel数 + 1) × 输出channel数):
(7×7×3+1)×64=9472
如果是使用三个3×3卷积替代7×7卷积(相同感受野),其计算量:
3×3×3×112×112×64+3×3×64×112×112×64+3×3×64×112×112×64=21676032+462422016+462422016=946520064≈946.5M
参数量:
(3×3×3+1)×64+(3×3×64+1)×64+(3×3×64+1)×64=1792+73856=75648
通过减少中间层的卷积核channel来减少其计算量:
3×3×3×112×112×24+3×3×24×112×112×32+3×3×32×112×112×64=8128512+86704128+231211008=326043648≈326M
参数量:
(3×3×3+1)×24+(3×3×24+1)×32+(3×3×32+1)×64=672+6944+18496=26112
由此可见,这种情况下,多个卷积层堆叠之后将会增加计算量。应该是由于输入channel和输出channel差距较大,在堆叠卷积层的第一层中进行升维后,后续的卷积层的计算量和参数量同时会大幅增加。这样就说明了使用堆叠的小卷积核替代大卷积核能够减少参数量和计算量的结论成立的前提是输入的channel和输出的channel相同。(升维操作对大卷积核只影响一次,但是对于堆叠的小卷积核却能影响多次)
缺点:
- 缺少模块化设计,不够优雅。
- insight,先出的结构,但是work的原理后续依然有许多人研究,因此更像是偶然所得。
- 有部分路径实际上是无效的,可被剪枝。
- 只在深度上进行探索,还能结合多尺度特征,在宽度上进行网络表现的提升。(不能算是严格意义上的缺点,如果只是把shortcut和拟合残差当成一种新的思路是相当的有启发性的)
ResNext
Residual Attention Module
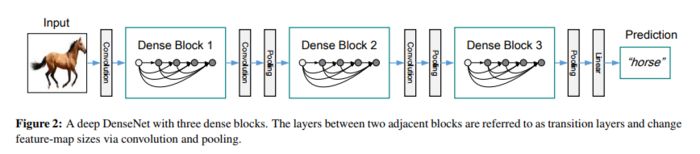
DenseNet(2016)
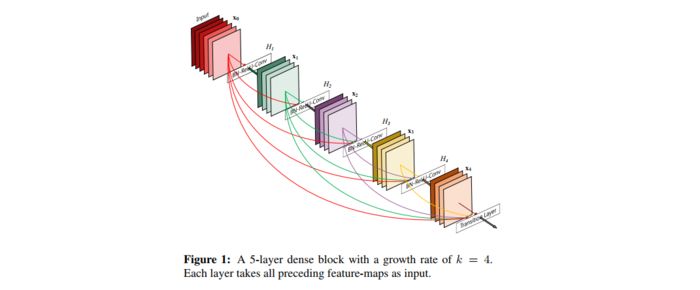
DenseNet与ResNet类似,都是利用short path来提升神经网络的性能。他与ResNet的区别在于连接方法以及连接的稠密程度。我们知道ResNet的连接方法是在残差结构中,将输入与经过二到三层卷积网络后的输出进行逐点累加,这样的操作要求输入与输出的尺寸、通道数是相同的(如果残差结构的第一个卷积层进行了下采样,那么相应的被逐点相加的输入也需要使用1×1,stride=2的卷积层进行下采样,确保尺寸、通道数一致)。而DenseNet的连接方法为特征图拼接(concatenate),其本质为特征图重用。在Dense Block中,每层都会与前面的所有层在channel维度上进行拼接,并作为下一层的输入。对于一个L层的Dense Block,一共包含了$\frac{L(L+1)}{2}$个连接,显然这比ResNet要稠密得多。
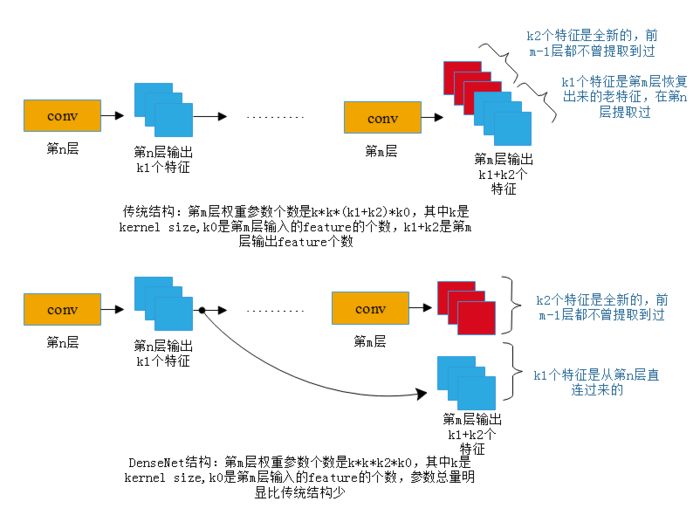
DenseNet减少参数总量的方式如上图所示,通常的卷积结构会对之前卷积层提取的特征重新进行提取。但是DenseNet的特殊结构,将之前所有卷积层提取到的特征图都作为当前层的输入,这就意味着当前层的输出不需要再次对之前卷积层的特征进行重复提取,只需要提取全新的特征即可,这样可以有效的减少卷积层的输出channal数从而减少参数量。每一个卷积层新提取的特征图像的数量称为增长率(growth rate)k。
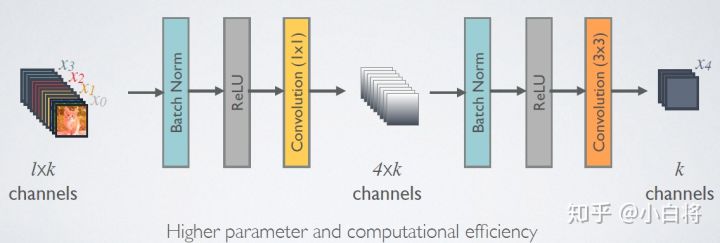
对于每一个卷积层,都是以BN-ReLU-Conv的顺序进行计算的。由于后面卷积层的输入的channal数将会非常巨大,因此在Dense Block内部可以采用bottleneck结构降维从而减少计算量,即在原有结构中增加1×1卷积,将输入到3×3卷积的特征图的channal数量降低至4k,再将这4k张特征图直接作为3×3卷积的输入,得到k张新的特征图。这种结构作者取名为DenseNet-B。
对于Transition层,是用于连接两个相邻的Dense Block,并缩小特征图尺寸。由于Dense Block的连接方式,需要相连接的每个层的输出尺寸相同,但是对于卷积网络,下采样进行抽象特征的提取是不可避免的,因此需要一个桥梁连接不同尺寸的Dense Block。
Transition层正是这样的一座桥梁。他包含一个1×1卷积和2×2的AvgPooling,具体结构为BN+ReLU+1×1 Conv+2×2 AvgPooling。除了缩小特征图的尺寸,Transition层还能起到压缩模型的作用。假定Transition上接的Dense Block得到的特征图channels数为m,Transition层中的卷积层可以产生$\lfloor \theta m \rfloor$个特征,其中$\theta \in (0,1]$是压缩系数。当$\theta = 1$时,特征个数没有变化,即无压缩;当压缩系数小于1时,这种结构称为DenseNet-C,文中使用$\theta = 0.5$。
对于在DenseBlock中使用bottle neck结构,Transition层中的压缩系数小于1的DenseNet,作者取名为DenseNet-BC。
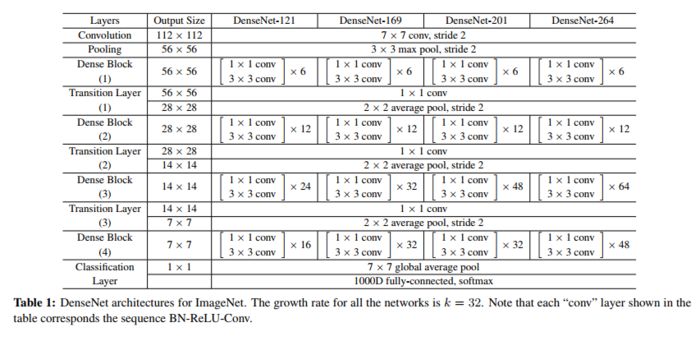
优点:
- 这种结构通过特征图的复用,减少的了每次卷积产生特征图的数量,从而减少卷积核的数量即卷积的参数量。
- 通过稠密连接提升了信息和梯度在整个网络中的流动性。
- 多尺度特征结合的思想。
缺点:
- 由于稠密连接,每一层的输入是前面每一层的输出,所以在没有经过框架的特殊优化前,DenseNet需要频繁读取内存以读取前面的所有层。
- 反向传播更复杂,训练速度较慢。
- 深度不如ResNet深。
MobileNet V1/V2/V3
MobileNet V1(2016)
其实MobileNet V1只需要一句话就能简介完毕,就是把VGG中标准卷积层替换为深度可分离卷积。
那么什么是深度可分离卷积呢?
其实在2012年就已经有人提出了可分离卷积的概念。可分离卷积主要有两种类型,空间可分离卷积和深度可分离卷积。
空间可分离就是将一个大的卷积核变为两个小的卷积核,比如:
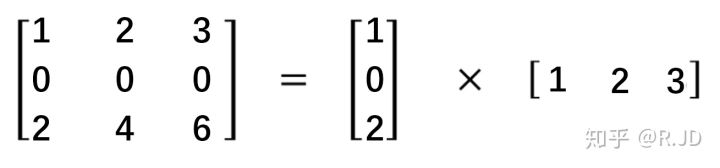
这不在MobileNet的范围内,因此不再赘述。
在介绍深度可分离卷积前,我们先复习一下常规的卷积操作是什么样的: 假设一张5×5×3的图片经过padding后(padding=1)输入到kernel size为4的3×3卷积核的卷积层,那么卷积核的总参数量应为3×3×3×4=108,计算量为(3×3×3+3×3×3-1+1)×5×5×4=5400,最终输出4张特征图。
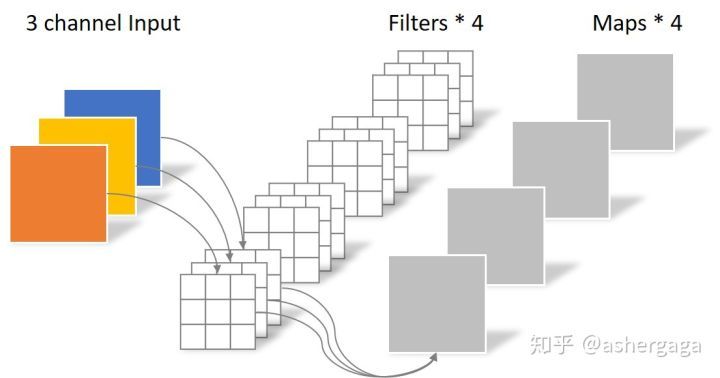
而对于深度可分离卷积,则将卷积操作分为了两部分,逐通道卷积(DepthWise)和逐点卷积(PointWise)。
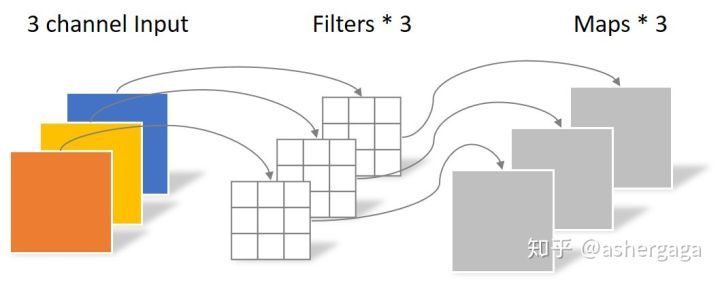
首先对输入图像进行逐通道卷积,逐通道卷积的一个卷积核只负责一个通道,输入图像的一个通道只被一个卷积核卷积。
还是以一张5×5×3的输入图片为例,首先经过逐通道卷积,卷积核的数量与输入图片的channels数相同且一一对应,所以输出的特征图数量与输入图像的通道数相同,这里输出的特征图的数量为3。该部分的参数个数为3×3×3=27,计算量为(3×3+3×3-1+1)×5×5×3=1350。
由于这种运算对输入层的每个通道独立进行卷积运算,没法有效利用不同通道在相同空间位置上的特征。因此还需要逐点卷积进行特征融合。
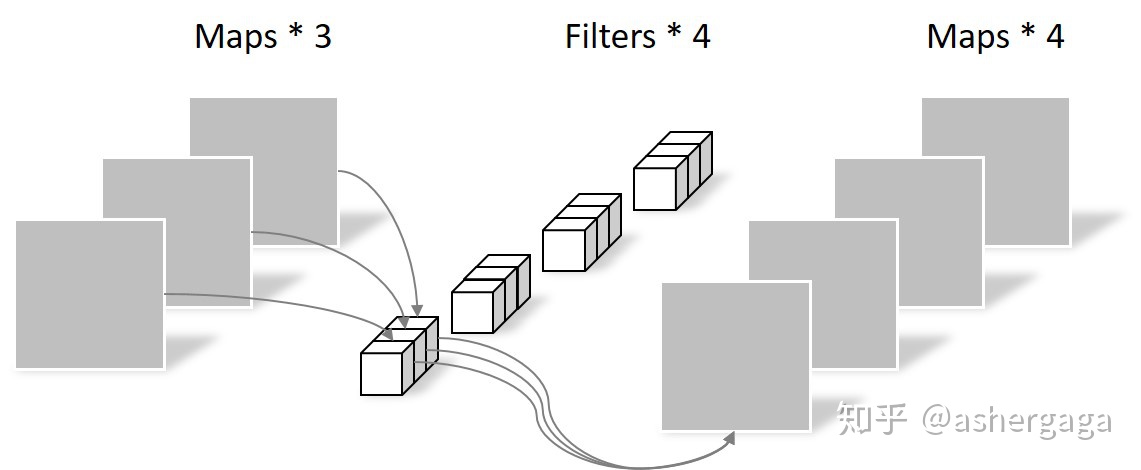
逐点卷积与常规卷积类似,他的卷积核的尺寸为1×1×M,M为上一层的通道数。这里的卷积运算会将上一步的特征图在深度方向上进行加权生成新的特征图,有几个卷积核就有几个输出的特征图。在本例中,最后生成了4张新的特征图,所以该部分的参数个数为1×1×3×4=12,计算量为(1×1×3+1×1×3-1+1)×5×5×4=600。
将两部分的参数量相加:27+12=39,为常规卷积的108个参数的13/36。计算量相加:1350+600=1950,也为常规卷积的5400次的13/36。(可根据公式推导得出参数量与运算量均下降为原来的$\frac{1}{输出channel数}+\frac{1}{卷积核_w × 卷积核_h}$)
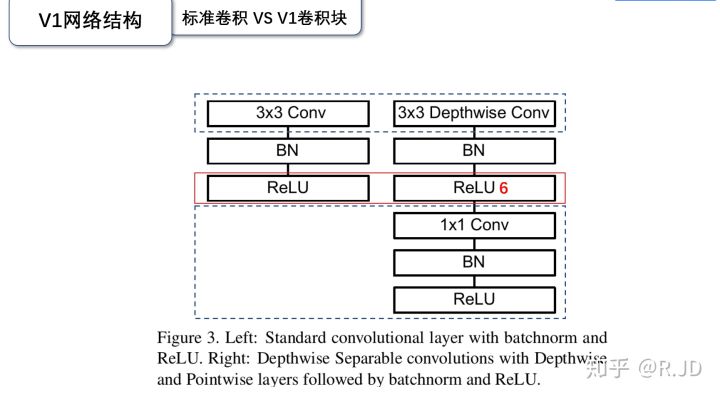
上图的虚线部分是不相同点。注意V1的卷积块中新引入了激活函数ReLU6。
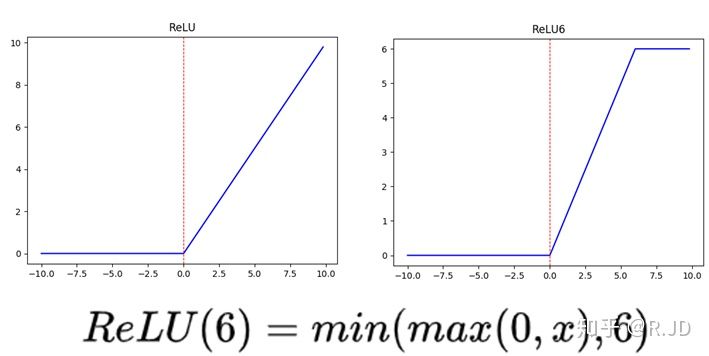
ReLU6与ReLU的区别在于多了最大输出值为6的限制,这是为了在移动端设备float16的低精度时,也能有很好的数值分辨率。如果对ReLU的激活范围不加限制,激活值有可能非常大,即分布范围可能会非常大,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。(这里所说的“低精度”,有人说不是指的float16,而是指定点运算(fixed-point arithmetic))
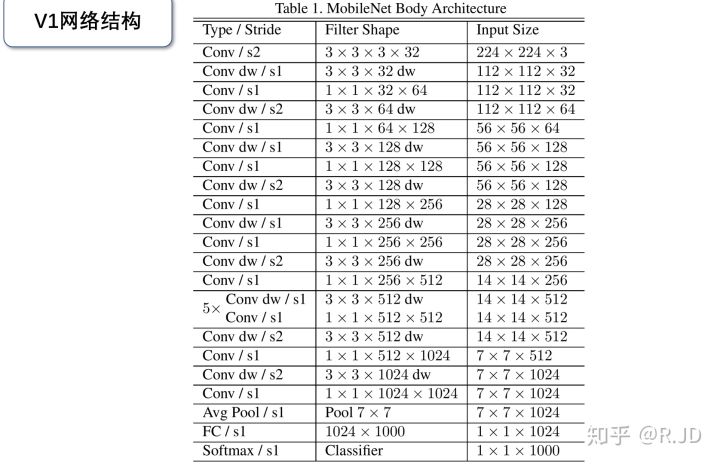
MobileNet V2(2017)
MobileNet V1的深度可分离卷积能在减少参数量、计算量,加快网络运算速度的同时得到标准卷积接近的结果,看起来是美好的。但是有人在实际使用时,发现逐通道卷积部分的卷积核比较容易训废掉,出来的卷积核有不少是空的。作者认为这是ReLU引起的。
作者做了个实验,简单地说,就是对一个n维空间中的一个“东西”做ReLU运算,然后(利用T的逆矩阵T-1恢复)对比ReLU之后的结果与Input的结果相差有多大。

实验的结果如上图,在低维空间做ReLU运算,很容易造成信息的丢失,而在高维度进行ReLU运算时,信息的丢失将会很少。
这就解释了为什么深度卷积的卷积核有不少是空的。于是作者便将ReLU替换成线性激活函数。
这里引入了Linear bottleneck这个概念,作者将ReLU替换成线性激活函数也是在Linear bottleneck的最后一个激活函数上进行的,前面两个激活函数依然还是ReLU6。(因为前两个卷积的输出通道数经过扩张之后,减小了ReLU6引起的特征丢失,但是第三个卷积是降维的,所以需要去掉ReLU6)
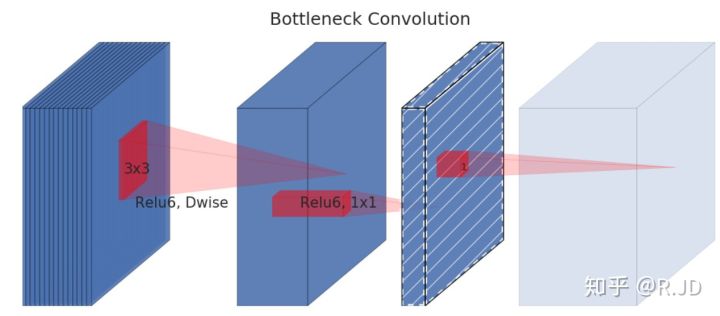
此外还有一个问题,逐通道卷积无法改变通道数量,如果输入的通道数量很少的话,逐通道卷积只能在低维度上进行,效果并不会很好,因此需要“扩张”通道。所以可以在逐通道卷积之前使用逐点卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行逐通道卷积提取特征。

也就是说,不管输入通道数是多少,经过第一个逐点卷积升维之后,逐通道卷积都是在原输入维度的6倍维度上进行。
除了上述的Linear bottleneck和Expansion layer,MobileNet V2还有引入了和ResNet类似的shortcut结构,如下图所示。
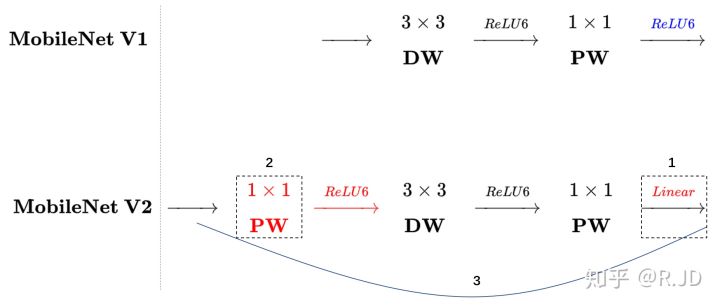
以上这部分与残差块相关的结构统称为Inverted residuals(与resuduals block的区别在于,resuduals block是先降维后升维,这里是先升维后降维)。
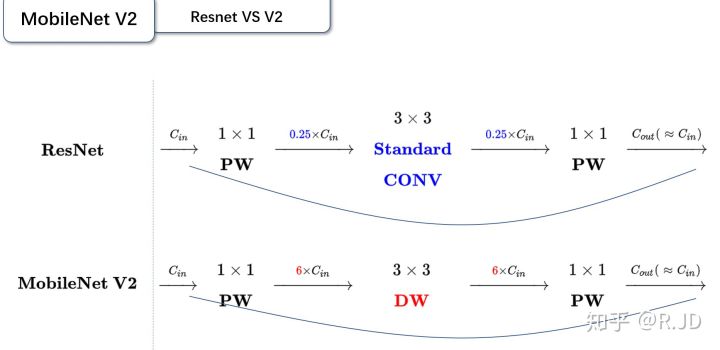
MobileNet V2与ResNet都采用了1×1->3×3->1×1的Block,并都使用了Shortcut结构,但是两者依然存在不同的地方(相邻Block之间不升维的情况):
ResNet先对输入降维(0.25倍)、卷积、再升维到输入的维度。
MobileNet V2则是先对输入升维(6倍)、卷积、再降维的输入的维度。
两者的操作正好相反。
总结起来,MobileNet V2的特点可以用以下的图片概括:
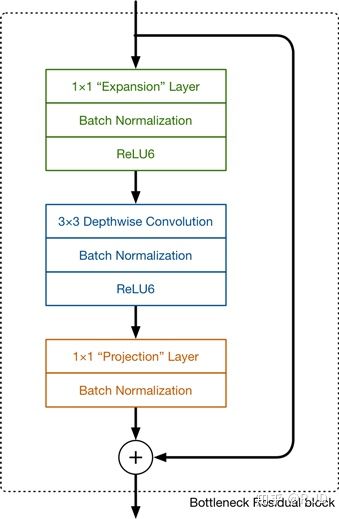

当步长为2时,因为输入与输出的尺寸不符,因此不能添加shortcut结构,其余均与步长为1时一致。
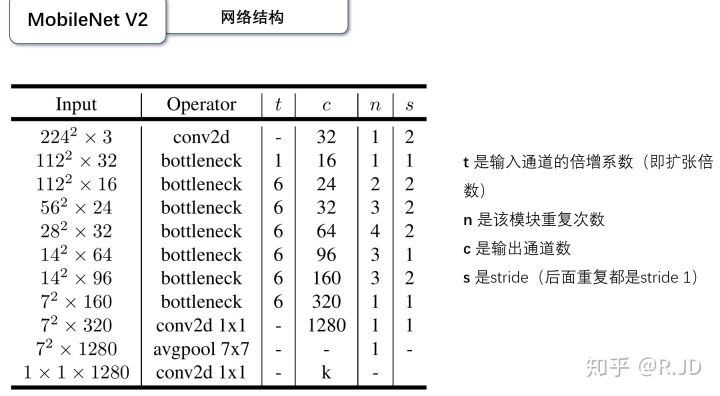
MobileNet V3(2019)
0.网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好) 1.引入MobileNetV1的深度可分离卷积 2.引入MobileNetV2的具有线性瓶颈的倒残差结构 3.引入基于squeeze and excitation结构的轻量级注意力模型(SE) 4.使用了一种新的激活函数h-swish(x) 5.网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt 6.修改了MobileNetV2网络端部最后阶段
SE Block https://zhuanlan.zhihu.com/p/47494490 SENet继残差设计之后,成为神经网络另外一个标配。 h-swish激活函数 https://zhuanlan.zhihu.com/p/70703846 待补充
SENet
Stacked Hourglass Networks
DetNet
Deformable convolution Networks
SKNet
RetinaNet
HWNet V1/V2
CenterNet等Anchor free网络
其他经典网络
LeNet-5(1998)
LeNet-5是一个7层卷积神经网络(一般输入层不计,也许有人会问,这个网络的名字里面为什么有个5,其实这个网络的主干就是5层,两个卷积层+两个全连接层+输出层)。网络输入是一个32×32×1的灰度图像。
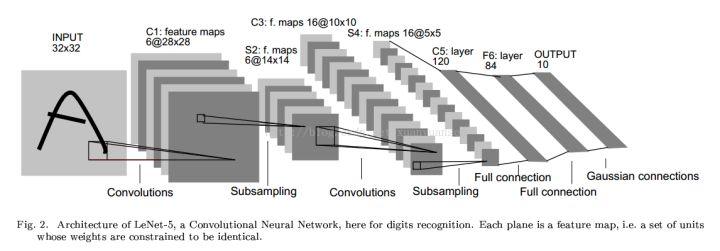
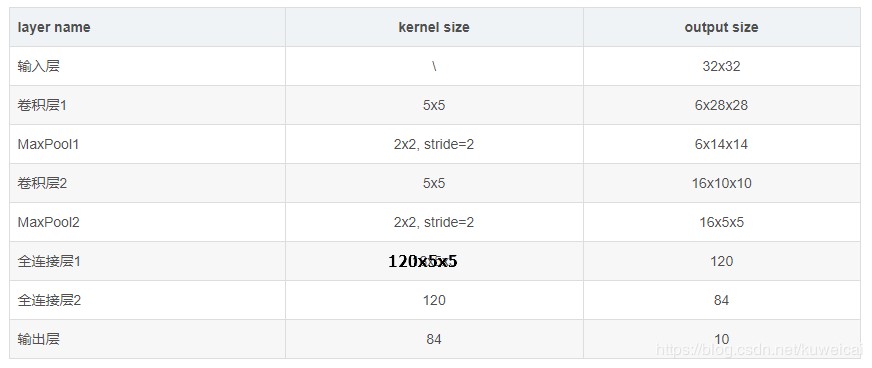
LeNet-5是一个7层卷积神经网络,总共有约6万(60790)个参数。
随着网络越来越深,图像的高度和宽度在缩小,与此同时,图像的channel数量一直在增加。
LeNet中选取的激活函数为Sigmoid。
注:
LeNet有一个很有趣的地方,就是S2层与C3层的连接方式。在原文里,这个方式称为“Locally Connect”。
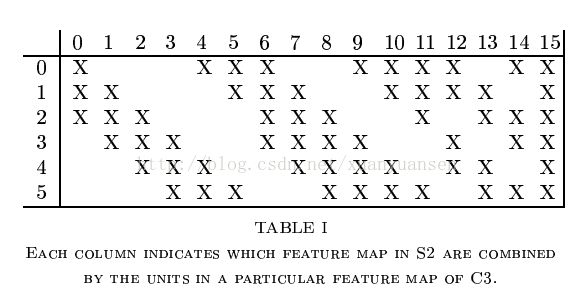
规定左上角为(0,0),右下角为(5,15),那么在(n,m)位置的“X”表示S2层的第n个feature map与C3层的第m个kernel进行卷积操作。例如说,C3层的第0个kernel只与S2层的前三个feature map有连接,与其余三个feature map是没有连接的;C3层的第15个kernel与S2层的所有feature map都有连接。这难道不就是ShuffleNet?
实例分割
FCN
目标检测与识别
目标检测发展历程

R-CNN
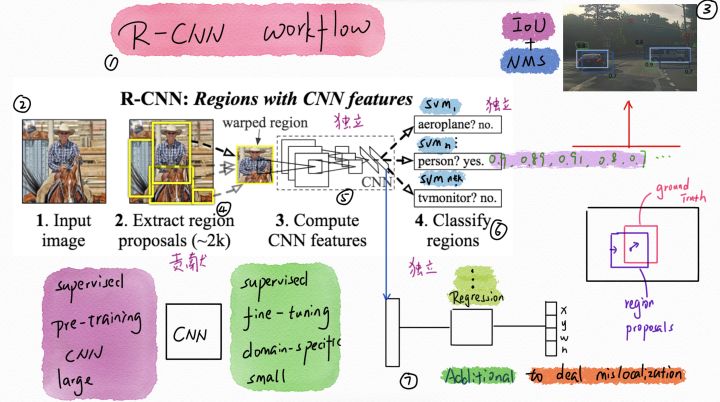
训练过程:
- 用SS(Selective Search,选择性搜索)提取候选区域(2000个)
穷举法或滑动窗口缺点:复杂度高,冗余候选区域;不可能顾及到每个尺度(指数级个数)。
SS:- 利用基于图的图像分割的方法初始化原始区域;
- 计算每两个相邻区域的相似度:
- 保持多样性:三种多样性策略:多种颜色空间,考虑RGB、灰度、HSV及其变种等;多种相似度度量标准,既考虑颜色相似度,又考虑纹理、大小、重叠情况等;通过改变阈值初始化原始区域,阈值越大,分割的区域越少。
- 给区域打分:不是每个区域作为目标的可能性都是相同的,因此需要衡量可能性,可以根据需要筛选区域建议个数。给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候呢,这个权重就会有太多的重合了,不好排序。文章做法是给他们乘以一个[0,1]的随机数,然后对于相同的区域多次出现的也叠加下权重,毕竟多个策略都说你是目标,也是有理由的嘛。这样我就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。
- 合并所有相邻区域中最相似的两块,直到合并完整(合并成为整张图片);
- 保存每次合并的结果,得到图片的分层表示。
输入: 一张图片 输出:候选的目标位置集合L 算法: 1: 利用切分方法得到候选的区域集合R = {r1,r2,…,rn} 2: 初始化相似集合S = ϕ 3: foreach 遍历邻居区域对(ri,rj) do 4: 计算相似度s(ri,rj) 5: S = S ∪ s(ri,rj) 6: while S not=ϕ do 7: 从S中得到最大的相似度s(ri,rj)=max(S) 8: 合并对应的区域rt = ri ∪ rj 9: 移除ri对应的所有相似度:S = S\s(ri,r*) 10: 移除rj对应的所有相似度:S = S\s(r*,rj) 11: 计算rt对应的相似度集合St 12: S = S ∪ St 13: R = R ∪ rt 14: L = R中所有区域对应的边框 - 用CNN提取区域特征
AlexNet,finetune最后一层(Softmax,21类,其中1类为背景,激活函数:Log loss),scale:227×227(在原始图片上截取正方形(猜测是向短边两边延展),向四面再各取16像素作为填充,超过的部分(短边两侧延展和四面填充)用均值,再直接变形为227×227的大小),对每个建议框得到4096维特征(FC7)。对待所有的推荐区域,如果其和Ground Truth的IoU>=0.5就认为是正例(同时确定类别?),否则就是负例。每轮SGD迭代(lr=0.001,预训练的十分之一),统一使用32个正例窗口(跨所有类别)和96个背景窗口,即每个mini-batch的大小是128。另外我们倾向于采样正例窗口,因为和背景相比他们很稀少。 - 对区域进行SVM分类
使用每个建议框的4096维特征(FC7输出)对每个目标类别训练SVM分类器(二分类,一对其余),识别该区域是否包含目标,共20个(存疑,论文没有明确,其他博文中有说21个,包含背景)。对于每个推荐区域的特征,将所有Ground Truth区域作为正例,与Ground Truth的IoU<0.3的推荐区域(包含背景,当前类别的部分,其他类别的正例)作为负例。
相对CNN,SVM可以采用少量样本训练得到较好的效果。(存疑)
使用NMS(IoU>=0.5)获取无冗余的区域子集。所有区域按分值从大到小排序,NMS剔除冗余后,剩余区域作为新的建议框子集。 - 边框校准(可选)
之后训练回归器,输入为每个建议框(与Ground Truth重合的IoU>0.6)通过CNN得到的特征图(Conv5输出),修正候选区域中目标的位置,对于每个类都训练一个线性回归模型判断当前框位置准确性。
缺点:
是一个多分步训练的过程。
训练的时间(18(finetune)+63(特征提取)+3(SVM/Bbox训练)=84小时)和空间开销大,提取的特征需要存放在硬盘上。
目标检测速度慢(47s/image(gpu))。
值得注意的点:
mAP,Bounding-box Regression,Hard Negative Mining(难分样本挖掘),Ablation study(切除研究法),非极大值抑制(non-maximum suppression NMS),输入矩形区域的处理
请参考RCNN 论文阅读记录
SPP-Net
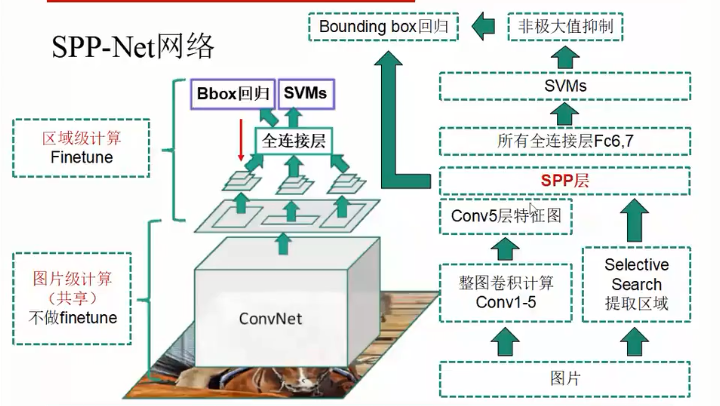
相较于R-CNN,做了两点改进:
- 直接输入整张图片进行特征提取(Conv5输出),所有区域共享卷积计算。在卷积结果上提取selective search得到建议框的特征图。
- 引入空间金字塔池化,为不同尺寸的区域在Conv5输出上提取特征,以映射到尺寸固定的全连接层上。
SPP层的位置位于Conv5之后,替代Conv5的Pooling层,分为3个level共21个Bin(4×4,2×2,1×1),每个Bin内使用Max Pooling。
为什么可以在提取特征之后提取SS建议框的特征图?因为对于输入图片,特征的相对位置是不变的,因此对于某个ROI,只需要对特征图的相应位置进行特征提取即可。
训练过程:
- 在ImageNet上对CNN模型进行pre-train。(与R-CNN相同)
-
使用SS得到建议区域,对CNN模型finetune fc6、fc7、fc8层
(因为(感受野太大)计算困难,效率低,所以不对SPP层之前的卷积网络进行finetune),并得到所有SS区域的SPP层特征和fc7层特征。-
如何将SS的建议框映射到特征图中?
假设每一层的padding都是p/2,p为卷积核大小。对于feature map的一个像素(x’,y’),其实际感受野为:(Sx’,Sy’),S为特征图前所有层中步长的乘积。
然后对于region proposal的位置,左上角的映射:($\lfloor$ $\rfloor$向下取整, $\lceil$ $\rceil$向上取整)
x’ = $\lfloor$x / S$\rfloor$ + 1
右下角的映射:
x’ = $\lceil$x / S$\rceil$ - 1
如果padding大小不一致,那么就需要计算相应的偏移值。另有说法:
spatial_scale = feature_map_size / input_img_size
roi_point = round(point × spatial_scale)感觉这里的round()不精确,参考:https://www.runoob.com/w3cnote/python-round-func-note.html
`个人感觉和上面的说法类似,只需要参照上面的取整方法修改roi_point的计算公式即可。 -
SPP如何实现?
设卷积conv5输出的特征图尺寸为a×a,当前金字塔层的bins为n×n,则有:
windows_size = $\lceil$a / n$\rceil$
stride = $\lfloor$a / n$\rfloor$
-
- 使用fc7层特征训练SVM分类器。(与R-CNN相同)
- 使用SPP层特征训练Bounding box回归模型。
缺点:
是一个多分步训练的过程。
训练的时间(16(finetune)+5.5(特征提取)+4(SVM/Bbox训练)=25.5小时)和空间开销大,提取的特征需要存放在硬盘上。
新问题:不能finetune SPP层之前的所有卷积层参数。
Fast R-CNN
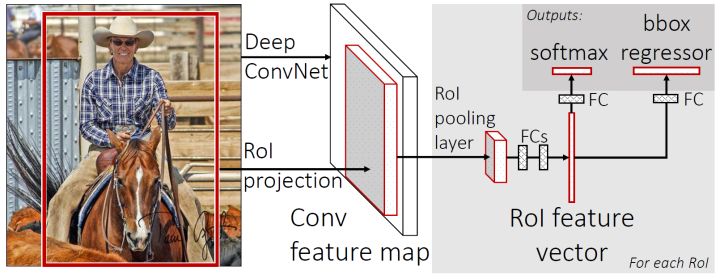
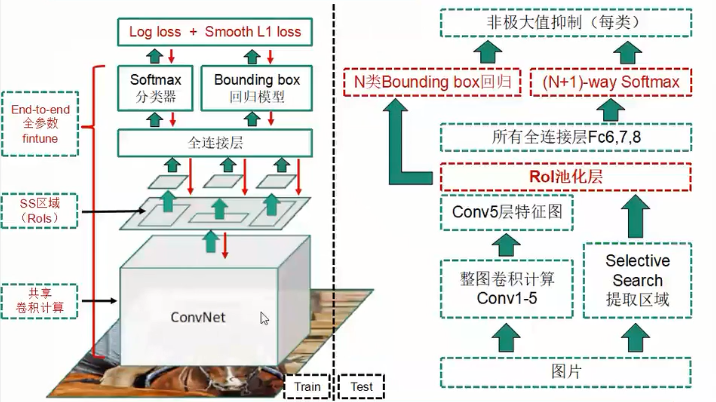
与上述两个网络相比更快的训练测试速度,更高的mAP,训练过程是端到端单阶段的(多任务损失函数,multi-task loss),所有层的参数都可finetune(取消SPP层),不需要离线存储特征。
在SPP-Net的基础上,Fast R-CNN引入了两个新技术:
感兴趣区域池化层(RoI pooling layer):取代SPP层;
多任务损失函数(Multi-task loss):SVM与Bbox Regression两个头合二为一,用一个统一的损失函数(Log loss+Smooth L1 loss)进行梯度下降。
RoI pooling:
SPP的单层特例,将RoI区域的卷积特征拆分成H×W网格(例如VGG为7×7,因为原始的VGG在conv5后的max pooling得到的也是7×7的图像,这样做和原始vgg的fc1是兼容的),在每个Bin中进行Max pooling。如果RoI在特征图上映射的大小无法被bin在行和列上的个数整除,则有两种方法,一种是将多余的特征图上的点舍去,另一种是将余出的点放在行和列上的最后一个bin中。
舍去多余的点将造成很大的误差,因此后续有RoI align进行改进。
由于RoI之间可能存在重叠区域,反向传播过程中,为偏导之和。???
参考:https://zhuanlan.zhihu.com/p/59692298、max pooling的反向传播
Multi-task loss:
同时考虑分类问题和定位问题,通过$\lambda$(文中为1)协调两个任务的权重。
\(L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u\geq1]L_{loc}(t^u,v)\)
分类器loss:
\(L_{cls}(p,u)=-logp_u\)
$u$为Ground Truth类别
对每个RoI,分类器输出的概率分布$p=(p_0,…,p_K)$(共有K+1类)
若$p_u$无限接近于1,即分类器的预测结果为$u$,$L_{cls}(p,u)$则无限接近于0($p_u$越大,$L_{cls}越小$)。
Bbox回归Smooth L1 loss:
指示函数$[u\geq1]$:
物体类别($u\geq$ 1):1,有回归loss;
背景类别($u=0$):0,没有回归loss
\(L_{loc}(t^u,v)=\sum_{i\in\{x,y,w,h\}}smooth_{L_1}(t^u_i-v_i)\)
smooth L1 的分段是为了避免出现离群点使x过大,导致loss值过大。
$t^u=(t_x^u,t_y^u,t_w^u,t_h^u)$表示预测的x,y,w,h与Ground Truth的x,y,w,h经过$t_x=(G_x-P_x)/P_w$(y类似)和$t_w=log(G_w/P_w)$(h类似)的转换。这里有点归一化的意味。
$v=(v_x,v_y,v_w,v_h)$表示实际上需要进行的偏移,例如$v_y=(G_y-B_y)/B_h$,$B_y$指SS得到的Bbox的中心点的y坐标。(待考证)
Mini-batch sampling:
分层抽样(Hierarchical sampling):
Batch_size(128)=images(2)*RoIs(64)
即每个batch取两张完整的图片,再从每张图片中取64个RoI。128个RoI中,正例(包含物体,与Ground Truth的IoU>=0.5)占25%,负例(包含背景,与Ground Truth的IoU在[0.1, 0.5))占75%。这样做的目的是为了限制负例数量。
训练时间9.5小时,单图测试0.32s。
Faster R-CNN
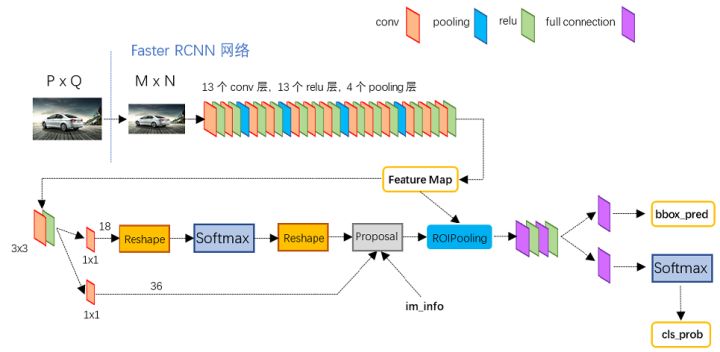
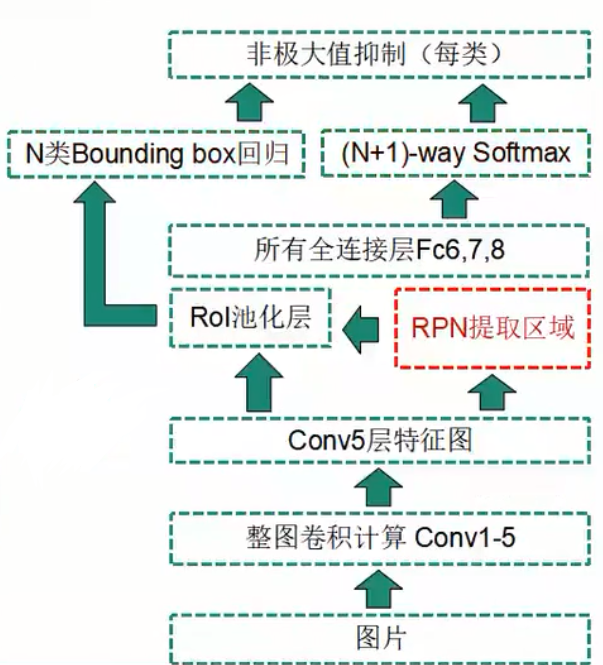
Faster R-CNN = Fast R-CNN + RPN(区域建议网络)
对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
与Fast R-CNN的区别在于使用RPN取代离线的Selective Search,解决性能瓶颈,提供量少(约300)质优(高precision,高recall)的Region proposals。
RPN:
RPN是一种全卷积神经网络。
输入:conv5输出的特征图
1) 3×3卷积,卷积核个数:256(ZF网络,vgg为512),步长:1×1,padding:1×1,激活函数:ReLU
为什么使用3x3的滑窗而不是2x2或者其他,个人理解:因为3x3在原图像的感受野是228x228, 对于尺度为128,256, 512的anchor设计来说,对于128x128的region proposal, 228x228是个很不错的选择(包含了上下文信息), 256尺度的跟228差不多, 512x512的只利用了中心的228x228的特征(虽然不是很好,但也凑合), 所以选择3x3的滑窗也算是一个技巧,目的是让这个滑动窗口的感受野跟region proposal的尽可能接近,这样去分类和做窗口回归才会更准。
2.1) Region proposals部分;1×1卷积,卷积核个数:4k,步长:1×1,输出k组proposals的offsets(r,c,w,h)
2.2) Classification部分:1×1卷积,卷积核个数:2k,步长:1×1,输出k组(object score,non-object score)
k表示anchor box类型数,通常情况下为9(3×3)。
3种原始图片上的尺度(scale):128,256,512
3种宽高比(ratio):1:1,1:2,2:1
3种尺度和3种宽高比相互组合,形成9种anchor。
anchor总数量为W×H×k,表示conv5特征图(W×H)的每个点上有k个anchor。
RPN的loss:
\(L(\{p_i\},\{t_i\})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i,p_i^*)+\lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*)\)
除于$N_{cls}$和$N_{reg}$(进行分类和回归的anchor个数,256,~2400???)以及使用$\lambda$(取值为10)加权是为了进一步平衡两个loss。$p_i^{}$指示函数,如果当前anchor为正例,真实标签$p_i^{}$为1,如果当前anchor为正例,则为0。
Classification部分:分为object和non-object两类,使用softmax激活和cross-entropy loss。
Regression部分:获得bounding box坐标,使用Smooth L1 loss:
$t_x=(x-x_a)/w_a,t_y=(y-y_a)/h_a$
$t_w=log(w/w_a),t_h=log(h/h_a)$
$t_x^*=(x^*-x_a)/w_a,t_y^*=(y^*-y_a)/h_a$
$t_w^*=log(w^*/w_a),t_h^*=log(h^*/h_a)$
$x,x_a,x^*$分别对应预测框,anchor框,ground truth框的中心点x坐标。y,w,h类似。
训练rpn的mini-batch:
单张图片
128个正样本(anchors):IoU>0.7的anchor框(或最大的IoU,因为有可能不存在IoU>0.7的anchor框)
128个负样本(anchors):IoU<0.3的anchor框
训练流程(六步交替法):
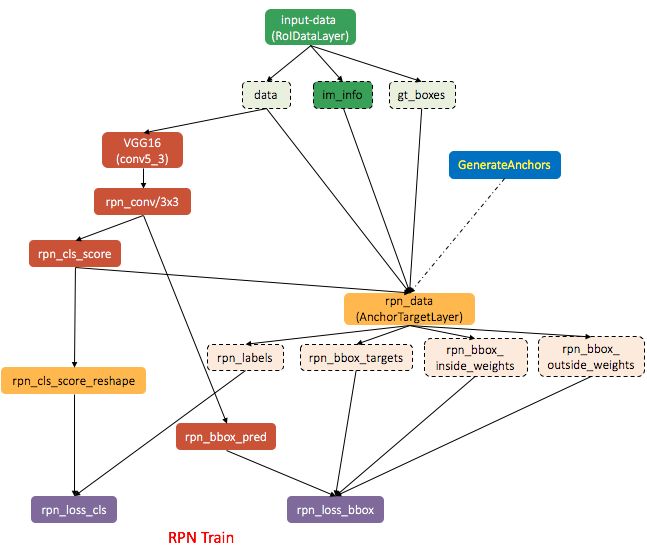
- 使用ImageNet预训练后的参数将模型初始化,对RPN进行训练。
- 通过训练后的RPN得到Region proposals。
- 训练Fast R-CNN(除RPN以外的部分称为Fast R-CNN)
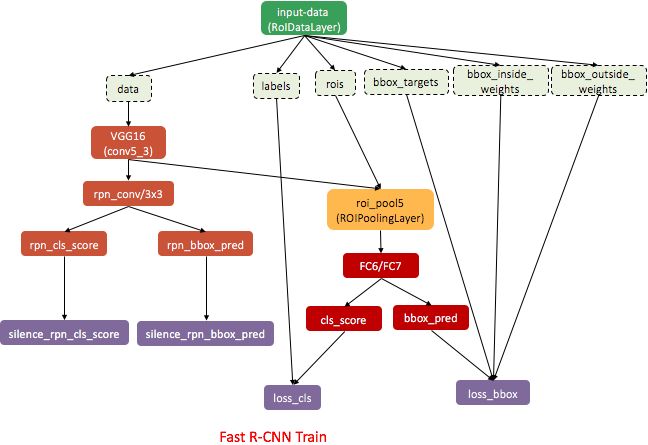
使用ImageNet预训练后的参数将模型初始化,与训练RPN时的卷积层不共享,由训练好的RPN提供Region proposals。 - 调优RPN
使用训练Fast R-CNN得到的卷积层参数对其初始化,固定卷积层参数,finetune剩余层。得到更精细的Region proposals。 - 通过调优后的RPN得到Region proposals。
- 调优Fast R-CNN
与调优RPN时的卷积层共享,固定卷积层参数,finetune剩余层。由调优好的RPN提供更精细的Region proposals。
训练流程(end2end):
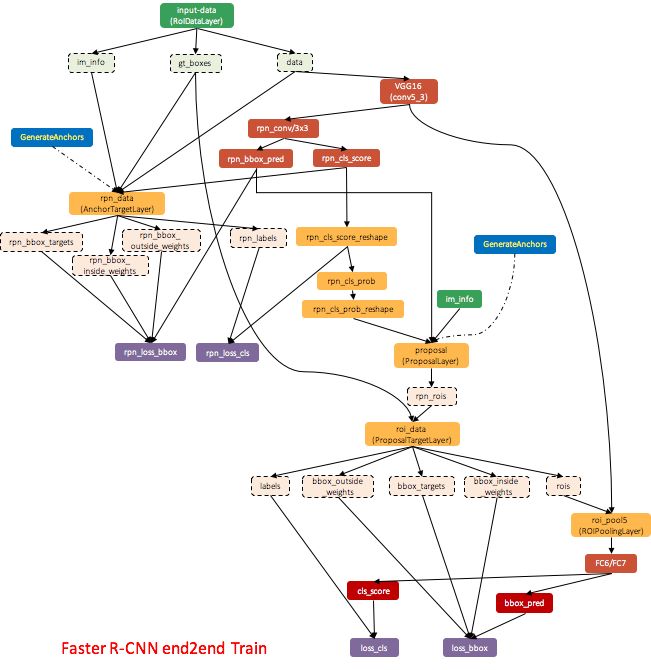
此训练方式比六步交替训练快很多,但精度却没有损失。此方式融合了RPN训练Fast R-CNN训练,但Fast R-CNN的input_data(原来为通过RPN得到的离线Region proposals数据)换成了roi_data由ProposalTargetLayer来完成对rois、labels、bbox_targets、bbox_inside_weights、bbox_outside_weights数据的生成。融合的训练过程需要计算四个损失函数,细节可参考:http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/。
存疑点:
- RPN训练的第一个batch是如何采样的?当时的正例负例怎么确认? 直接取全部anchor,去除越界的anchor,通过与Ground Truth的IoU判断正例负例,而不是对proposal regions进行正负例判断。简而言之,训练的样本就是满足一定IoU的anchor,这不需要通过预测得到。
- RPN loss中的$N_{reg}$的2400是如何取得的?
论文中$N_{reg}$是feature map的size,但是实际的代码实现的时候,$N_{reg}/\lambda$是batch size。batch size为256,$\lambda$为1。假设$\lambda$为10,实际上$N_{reg}$也在2400左右(2560)。
https://www.zhihu.com/question/65587875
R-FCN
Mask R-CNN
U-NET
YOLO
YOLO v2
YOLO v3
YOLO v3-tiny
YOLO v4
YOLt
SSD
cornernet
CornerNet创新来自于多人姿态估计的Bottom-Up思路(先对整个图片进行每个人体关键点部件的检测,再将检测到的人体部位拼接成每个人的姿态,缺点就是会将不同人的不同部位按一个人进行拼接),预测corner的heatmaps,根据Embeddings vector对corner进行分组,其主干网络也来自于姿态估计的Hourglass Network。
corner pooling
hourglass network
embedding vector
centernet-keypoints
网络中的各种细节
反向传播的推导
神经元数量计算
输出维度是多少,神经元就有多少。如AlexNet的第一个卷积层输出为55×55×96,那么就有55×55×96=290400个神经元。
输入输出尺寸计算
输出_w=(输入_w-kernel_w+padding_l+padding_r)/stride_w+1
输出_h=(输入_h-kernel_h+padding_t+padding_b)/stride_h+1
池化卷积均可用此公式计算,注意横向、纵向有所区别时需各自计算,有时四边padding不同也需注意。
参数量计算
-
卷积网络
参数量 = (卷积核_w × 卷积核_h × 输入channel数 + 1) × 输出channel数
括号内的为一个卷积核的参数量,+1表示bias,使用Batch Normalization时不需要bias,此时计算式中的+1项去除。
-
全连接网络
参数量 = (输入神经元数量 + 1) × 输出神经元数量
每一个输出神经元连接着所有输入神经元,且每个输出神经元还要加一个bias。
FLOPs(floating point of operations,浮点运算数)计算
-
卷积网络
FLOPs = [(输入channel数 × 卷积核_w × 卷积核_h) + (输入channel数 × 卷积核_w × 卷积核_h - 1) + 1] × 输出_w × 输出_h × 输出channel数
= 2 × 输入channel数 × 卷积核_w × 卷积核_h × 输出_w × 输出_h × 输出channel数(输入channel数 × 卷积核_w × 卷积核_h)表示一次卷积操作中的乘法运算量,(输入channel数 × 卷积核_w × 卷积核_h - 1)表示一次卷积操作中的加法运算量,+1表示bias,每个输出的神经元都对应一次卷积计算,因此需要乘于输出_w × 输出_h × 输出channel数。
在计算机视觉论文中,常常将一个‘乘-加’组合视为一次浮点运算,英文表述为’Multi-Add’,运算量正好是上面的算法减半,此时的运算量为:FLOPs = 输入channel数 × 卷积核_w × 卷积核_h × 输出_w × 输出_h × 输出channel数
-
全连接网络
FLOPs = [输入神经元数量 + (输入神经元数量 - 1) + 1] × 输出神经元数量
中括号的值表示计算出一个神经元所需的运算量:要得到一个输出神经元,需要对每个输入神经元做一次乘法,再将乘法得到的结果进行求和,即(输入神经元数量 - 1)次加法运算,+1表示bias。
链接数计算
-
卷积网络
链接数 = 局部连接的输入层神经元数(输入channel数 × 卷积核_w × 卷积核_h + 1) × 卷积层神经元数(输出_w × 输出_h × 输出channel数)
-
全连接网络
链接数 = (输入神经元数量 + 1) × 输出神经元数量
感受野计算
\(r_i=s_i*(r_{i+1}-1)+k_i\) 需要从顶层往底层(靠近输入层)进行计算,$r_i$表示待计算层输出的一个像素点的感受野大小,$s_i$表示待计算层的步长,$k_i$表示待计算层的卷积核(池化窗口)大小,$r_{i+1}$表示待计算层上一层输出的一个像素点的感受野大小。此计算不需要考虑 padding size。
举个VGG16的例子:
conv5_3:3
conv5_2:1×(3-1)+3=5
conv5_1:1×(5-1)+3=7
maxpool4:2×(7-1)+2=2×7=14
conv4_3:1×(14-1)+3=16
conv4_2:1×(16-1)+3=18
conv4_1:1×(18-1)+3=20
maxpool3:2×20=40
conv3_3:1×(40-1)+3=42
conv3_2:1×(42-1)+3=44
conv3_1:1×(44-1)+3=46
maxpool2:2×46=92
conv2_2:1×(92-1)+3=94
conv2_1:1×(94-1)+3=96
maxpool1:2×96=192
conv1_2:1×(192-1)+3=194
conv1_1:1×(194-1)+3=196
所以在conv5_3的输出中,一个像素在输入图像中的感受野为196个像素。
https://zhuanlan.zhihu.com/p/41955458
参数初始化方法
归一化
模拟退火
模型蒸馏
分组卷积
深度可分离卷积
空洞卷积
转置卷积
反卷积
1×1卷积(NIN)
对于单通道(feature map数量为1)输入,单个1×1卷积核仅仅是将每个元素进行缩放,对特征来说没有意义。
不过卷积网络的输入(上一层的feature map)一般都是多通道的,在这里1×1卷积核的作用非常强大:
- 融合多个通道的特征。
- 对通道数进行降维/升维。
通过1×1卷积核的作用之后,feature map的长宽不变,但是通道数会改变(使用多少个1×1卷积核就输出多少通道数的feature)。 在GAP之前,要生成对应类别数的feature map,就要先用1×1卷积核进行卷积(10个类,就用10个1v1卷积核,这里有10个weight参数+10个bias参数)得到对应类别的特征图。
可变形卷积
Dropout
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
Dropout在每个训练批次中,通过忽略一部分的特征检测器(让一部分的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout简单的说就是:在前向传播的时候,让某个神经元的激活值以一定的(丢弃)概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
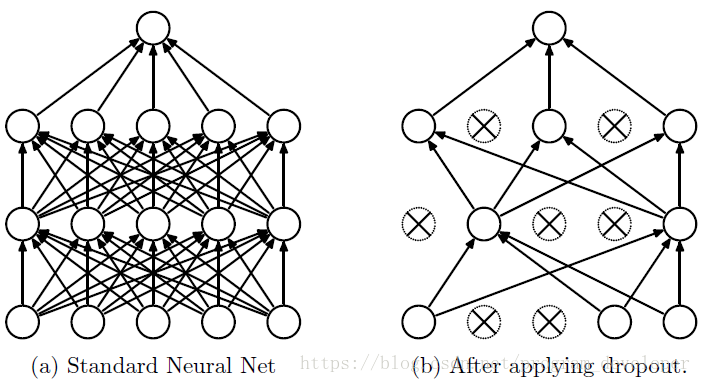
具体流程:
- 首先根据Dropout的(丢弃)概率p随机临时地删除网络中的部分隐藏神经元,即节点值暂时置为0。
- 然后将输入x送入到经过Dropout处理后的网络进行前向传播,然后把得到的损失结果在处理后的网络中反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)。
不断重复上述过程。
显然,被Dropout丢弃的神经元在该批次的学习中不参与前向传播和后向传播,在该批次学习结束后恢复原值,进入下一个学习批次。
在实践中通常有两种处理方式,一种是在训练时根据Dropout概率p随机丢弃节点(实际上也可丢弃节点对应的输入值),并对输入值乘以1/(1-p)进行放大;另一种是在训练时根据Dropout概率p随机丢弃节点,但不对输入进行缩放,而是在预测时对所有节点的权重乘以p进行缩小。前者将数值运算放在训练阶段,能够减小测试阶段的计算量,提升速度,称为inverted dropout。
训练时处理:
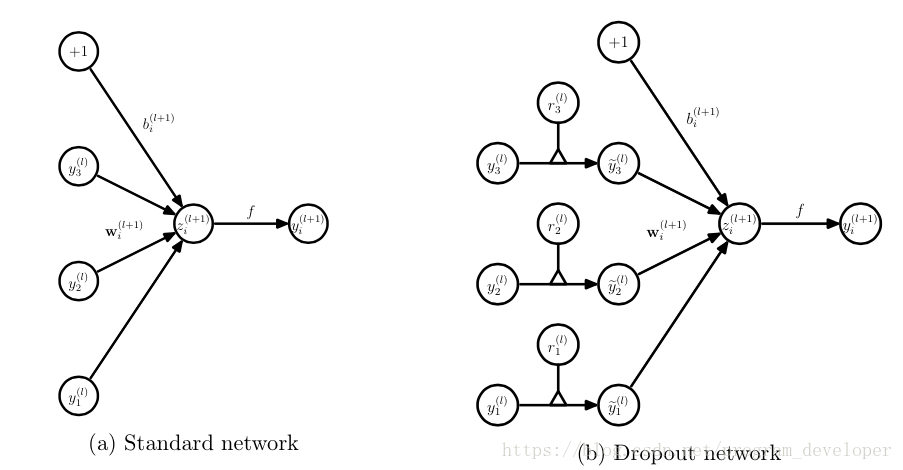
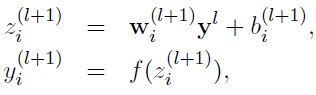
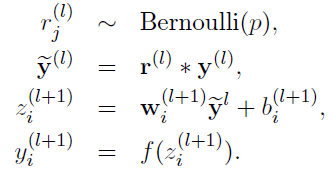
其中Bernoulli函数即为0-1分布发生器,随机生成一个0、1向量。假设将Dropout的概率p设置为0.4,即有40%的神经元的值置为0(丢弃40%的神经元),那么得到的z的值将为原来的60%(剩余60%的神经元)。因此我们通常需要对y进行放大,乘以1/(1-p),这里即为乘以5/3。如果未在训练时对y进行放大,那么在测试时就需要对权重进行缩小。
测试时处理:

防止过拟合的原理:
- 取平均的作用
Dropout过程就相当于对很多个不同的神经网络取平均。
我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。 - 减少神经元之间复杂的共适应关系
Dropout导致两个神经元不一定每次都在一个Dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,迫使网络去学习更加鲁棒的特征。 - 相当于对样本增加噪声
观点十分明确,就是对于每一个Dropout后的网络,进行训练时,相当于做了Data Augmentation,因为,总可以找到一个样本,使得在原始的网络上也能达到Dropout单元后的效果。比如,对于某一层,Dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,那么总能找到一个样本与Dropout后的结果相同。这样,每一次Dropout其实都相当于增加了样本。
总的来说,由于Dropout是随机丢弃,故而相当于每一个mini-batch都在训练不同的网络,可以有效防止模型过拟合,让网络泛化能力更强,同时由于减少了网络复杂度,加快了运算速度。还有一种观点认为Dropout有效的原因是对样本增加来噪声,变相增加了训练样本。
Dropout通常用于全连接层中和输入层中,很少见到卷积层后接Dropout,原因主要是卷积参数少,不易过拟合。
激活函数
ReLU
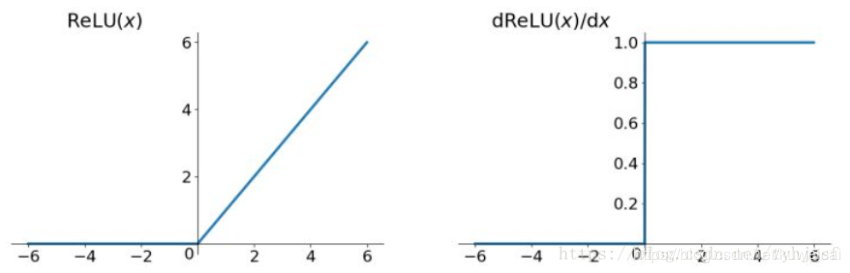
\begin{equation} ReLU(x)=max{0,x} \end{equation}
这个激活函数应该是在实际应用中最广泛的一个。
优点:
- x大于0时,其导数恒为1,这样就不会存在梯度消失(如在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失)的问题。
- 计算导数非常快,只需要判断x是大于0,还是小于0。
- 收敛速度远远快于Sigmoid和Tanh函数。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
缺点:
- none-zero-centered(非零均值, ReLU函数的输出值恒大于等于0),会使训练出现zig-zagging dynamics现象,使得收敛速度变慢。
- Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。因为当x小于等于0时输出恒为0,如果某个神经元的输出总是满足小于等于0的话,那么它将无法进入计算。
有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。
解决方法是可以采用MSRA初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
Softmax
损失函数
优化器
预处理方法
项目相关
Openpose
Openpose实现了二维单张图片的多人关键点实时识别,是一种bottom-up的方法。相比于将多人姿态估计问题转化为单人姿态估计问题的top-down,bottom-up方法首先检测出图中所有人的所有关键点,再对关键点进行分组,进而组装成多个人。因此这种方法的性能不会受到detector性能的影响,且运行时间不会随着图片中人数增加而增加。
其核心为CPM+PAF,那么就来简单了解一下这两个部分分别是什么吧。
CPM
CPM,Convolutional pose machines,是Openpose的前身,是CMU2015年的一个工作。这个工作主要针对的是单人的姿态估计。使用神经网络同时学习图片特征(image features)和空间信息(spatial context)。首先使用多个CNN进行图片特征的提取,再采用一个multi-stage的结构来学习空间信息。具体来说,每个stage的输入是原始图片特征和上个阶段输出的信念图(belief map),这个belief map可以认为是之前的stage学到的空间信息的一个encording。这样当前stage根据这两种信息继续通过卷积层提取信息,并产生新的belief map,这样经过不断的refinement,最后产生一个较为准确的结果。

下图可以明显看出空间信息的重要性,也展现了refinement的过程。
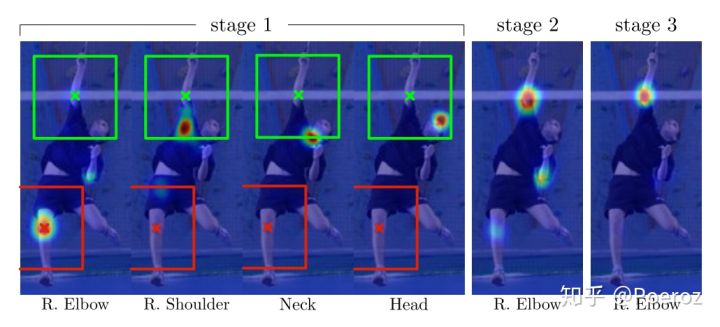
在stage1中出现了相对较多的错误定位,在stage2中由于有了stage1提供的空间信息,根据其他部位的位置可以对某个部位的位置进行纠正,后续的多个stage实际上也是在对前一个stage的belief map进行refinement,最后得到一个最为精确的belief map。
此外,这篇文章还提出了很重要的一点,就是通过中继监督(intermediate supervision)来解决梯度消失的问题。由于CPM包含了多个stage,因此网络的深度较深,容易出现梯度消失的问题导致网络无法收敛。在每个stage结束后给当前的belief map加一个监督,可以有效缓解梯度消失的问题,这在multi-stage网络中是一种较为常用的技巧。
PAF
PAF是Openpose的一个主要创新点,实际上就是在关键点之间建立的一个向量场,描述一个肢干(limb)的方向。有了描述关键点位置的heatmap(类似CPM的结果)和描述关键点间关系的PAF,使用二分图最大权匹配算法来对关键点进行组装,从而得到人体骨架。

F表示经过vgg-19前几层cnn提取得到的特征图,S和L分别表示heatmap和PAF,两者的数量分别为关键点的数量和肢干(应该×2,因为是二维向量)的数量,且两者都是pixel-wise的。这里与CPM很相似,都是使用多个stage不断进行refinement,后一阶段的输入是前一阶段的S、L和初始的F的结合。
那么heatmap和PAF的GT是怎么得到的呢?
对于heatmap来说,x,y上为某个人的某个关键点,则以其为中心,在对应的heatmap上使用二维高斯核对其进行处理,将点转换成峰值区域(peak),如果一张图片中有多个人的同一个关键点出现了重叠,那么对GT的该层heatmap上重叠区域的每个像素点取max。
PAF的GT,实际上是从连接的关键点a到关键点b的单位向量,每个肢干将会生成一个矩形范围(通过一个阈值进行设置),在矩形范围中的每个点都被认为是在肢干上,这些点的值即为单位向量(有x分量和y分量,因此一个肢干需要用两个vector map描述)。在矩形范围外的点为零向量。对于重叠的肢干区域,重叠区域的值取平均值进行计算(非零向量才参与均值计算)。
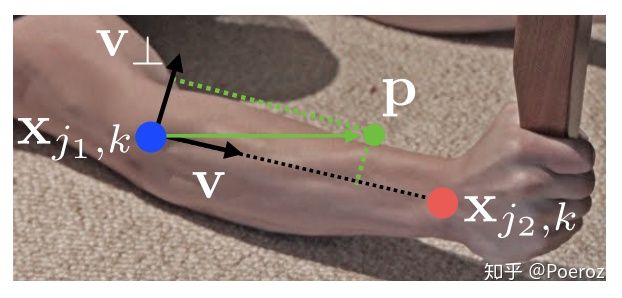
至于loss的计算,就是对每个stage的S和L分别计算L2 loss,最后所有stage的loss相加即可。
通过nms找出heatmap上每个part的候选点,再通过PAF选出真正的肢干。定义两个关键点之间组合的权值,实际上就是两点间各个像素点的PAF在两点组成的线段上投影的积分,如果各点的PAF方向与线段的方向越一致,权值就越大,这两点组成一个肢干的可能性就越大。
知道了如何计算两个候选点之间组合的权值,对于任意两个part对应的候选点集合,我们使用二分图最大权匹配算法可以给出一组匹配。但如果考虑了所有part之间的PAF,这将会是一个K分图最大权匹配问题,是NP-Hard问题。通过简化,可以将原问题划分为若干个二分图最大权匹配问题(匈牙利算法)。(这部分不太理解,有时间可以继续看看)
(参见)[https://zhuanlan.zhihu.com/p/104917833]
缺点
- 消耗显存
- 特殊场景下检测效果差
竞赛相关
Cascade rcnn
介绍Cascade rcnn前,需要先对Faster rcnn的流程进行回顾。
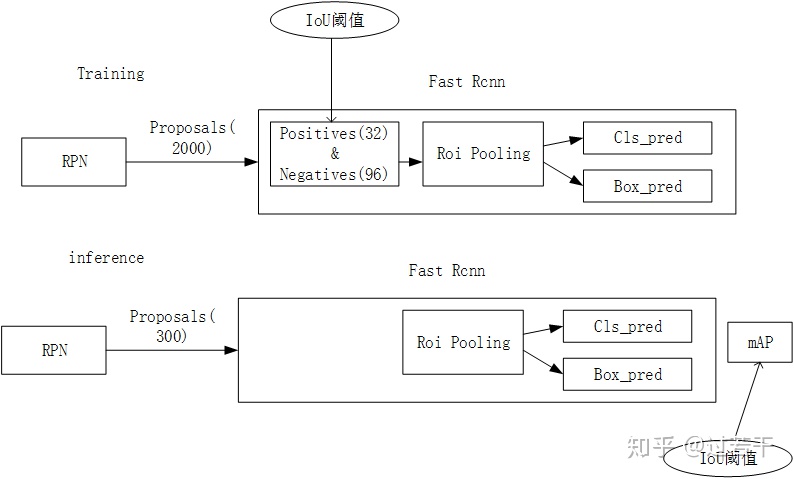
Faster rcnn中用到IoU阈值的有两个地方,分别时training时positive与negative的判定,和inference时计算mAP。论文中强调的IoU阈值指的是training时positive与negative的判定。 IoU阈值是一组需要精心挑选的超参数,IoU阈值取得越高,得到的positive样本更接近目标,因此训练得出的检测器定位更加精准。但是一味提高IoU阈值会引发两个问题,一是正样本过少导致训练的过拟合问题,二是训练和测试使用不同的阈值导致评估性能的下降。反之,IoU阈值选取的越低,得到的正样本更为丰富,有利于检测器的训练,但必然会导致测试时出现大量的虚检(close but not correct)。作者做了以下实验进行了佐证:

上图(c)中给出了经过一次回归之后,目标候选框与GT目标框匹配的IoU的变化,横轴代表回归前的IoU,纵轴代表回归后的IoU,不同颜色的曲线代表的是不同阈值训练的检测器。总体而言,经过回归后,目标候选框的IoU均有所提升,但是区别在于:IoU在0.55-0.6之间时,基于0.5的IoU阈值训练的回归器输出结果最佳(蓝色线);IoU在0.6-0.75之间,基于0.6的IoU阈值训练的回归器输出结果最佳(绿色线);IoU在0.75以上,基于0.7阈值训练出的回归器输出最佳(红色线)。以上结果表明,要得到定位精度较高的检测器(即IoU越大越好),必须选用较大的IoU阈值。
而图(d)中的结果表明,基于0.7IoU阈值训练出的检测器的AP反而是最差的,只有在选用IoU阈值为0.85以上进行评测时,结果才略好与蓝色线,依然劣于绿色线,验证了之前的分析:基于0.7IoU阈值训练出的检测器中正样本过少,因为正样本的多样性不够,容易导致训练的过拟合,因此在验证集上表现不佳。
作者由此探索是否有一种方法既能用较高的IoU阈值训练检测器,又能保证正样本的多样性足够丰富,提出了Cascade R-CNN,其核心思想就是“分而治之”。Cascade R-CNN是一个顺序的多阶段extension,利用前一个阶段的输出进行下一阶段的训练,阶段越往后使用更高的IoU阈值,产生更高质量的bndbox。Cascade R-CNN简单而有效,能直接添加到其它R-CNN型detector中,带来巨大的性能提升(2-4%)。
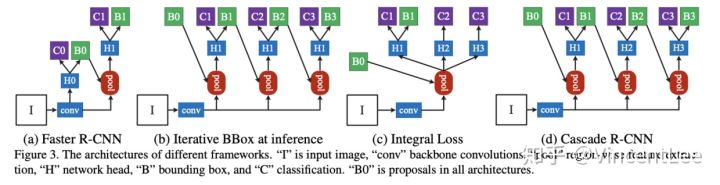
上图中的(b)与Cascade R-CNN的结构极为相似,区别在于只在测试时使用级联结构对Box多次回归,因此ROI检测网络部分“H1”是相同的,也意味着训练时使用的是单一的IoU阈值。这样做会带来以下问题:目标候选框经过0.5IoU阈值的检测器后样本的分布已经发生了改变。

可以看到每经过一次回归,样本都更靠近gt一些,样本的分布也在逐渐变化,如果还用0.5的IoU阈值,后面两个stage就会有较多的离群点,使用共享的H无法适应这样的样本分布的变化。
在Cascade RCNN的前向预测结构图中可以发现RPN输出的B0经过cascade检测分支,进阶提升的方式输出更精准的B1、B2、B3,最后以B3输出的bbox为最终结果,那么问题来了:C1、C2、C3输出的分类结果,我们应该信哪个?是按照C3的结果输出吗?
结合deploy.prototxt,可以发现是对C1、C2、C3三个分类结果求和取平均;但我在想,理论上H3输出的bbox更精准,C3的分类结果应该会更准,此时对C1、C2、C3三个分类结果加权求和会不会更好一点?
其实总结起来,Cascade R-CNN的思想就是级联IoU阈值不同且逐渐升高的RCNN Head,将前一个Head输出的预测框作为后一个Head的Proposal输入,以逐渐提高回归的精度。同时也能消除因为IoU阈值一次性设置过高而引起的正样本多样性不足带来的过拟合问题。
其余细节可参考: https://zhuanlan.zhihu.com/p/42553957 https://zhuanlan.zhihu.com/p/45036212 https://zhuanlan.zhihu.com/p/45037103 https://zhuanlan.zhihu.com/p/45331020 https://zhuanlan.zhihu.com/p/45421606
DCN V1(Deformable Conv)(2017)
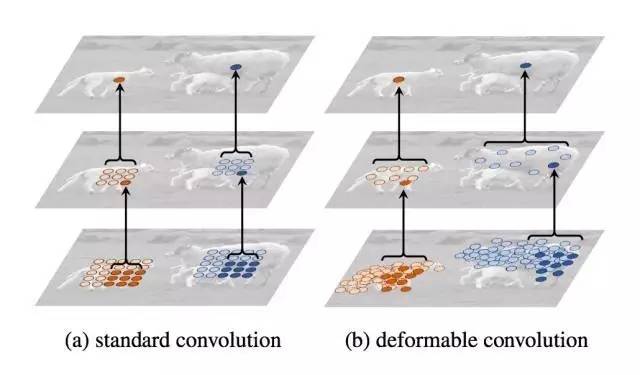
动机
我们都知道常规的卷积和池化这些操作,无论如何叠加,基本上得到的都是矩形框,这是不切合实际的,对不规则目标建模时会有非常大的局限性。通常解决这类问题的方法有两类:一是在数据集上进行扩增,让训练集包含所有可能的几何变化,例如使用仿射变换做数据增强,但这不是对所有场景都适用的;另一种是设计对几何变化不敏感的特征和算法,例如SIFT,这种方法在应对没有考虑到的或过于复杂的形变时较为无力。
导致上述问题的根本原因,还是在于CNN的过于固定的采用操作。实际上CNN是不具有旋转不变性和尺度不变性的,因此通常只能使用上述的第一类方法增强对不规则目标的建模。但这对于不规则的物体还是过于僵硬了,比如同一层特征图的不同位置对应的是不同形状的物体,但都是通过同一个卷积做计算。
空洞卷积
在介绍DCN之前,我们需要先对空洞卷积有一定的认识。
通常为了在增大感受野的同时不增大卷积核尺寸,需要对图像进行池化下采样。但是池化后,不可避免的将会丢失一些信息。在例如图像分割任务中,需要的是pixel-wise的输出,因此我们需要一种新的操作,不通过pooling也能有较大的感受野以获取更多的信息。空洞卷积(Delated conv)应运而生。

(a)普通卷积,1-dilated conv,卷积核的感受野为3×3
(b)空洞卷积,2-dilated conv,卷积核的感受野为7×7
此时实际的卷积核尺寸还是3×3,但是空洞为1,也就是对于一个7×7的图像patch,只有9个红色的点与3×3卷积核进行卷积,其余点都略过.也可以理解为卷积核的尺寸为7×7,但只有图中9个点的权重不为0,其余都为0。可以看到虽然卷积核尺寸只有3×3,但是这个卷积的感受野已经增大到7×7了(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv 的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv)。
(c)空洞卷积,4-dilated conv,卷积核的感受野为15×15
跟在两个1-dilated和2-dilated conv之后,能到达15×15的感受野。与传统的3个3×3卷积核堆叠的7×7感受野(与层数成线性关系)相比,空洞卷积的感受野是指数级的增长。
空洞卷积与普通卷积相比,除了卷积核的大小之外,还有一个膨胀率(dilation rate)的参数,用于表示膨胀的大小。
总的来说,空洞卷积的优点在于不进行pooling损失信息的情况下,扩大了卷积核的感受野,同时保证卷积核参数量和输出的特征图的大小不变。
DCN感觉是更为自由的dilated conv,同时还增加了池化上的deform。DCN主要包含了两个模块,Deformable Conv和Deformable Pooling。他们的优点是很方便的就能嵌入已有的模型中,不需要额外的监督信号。
Deformable Conv
我们先看看一般的卷积是怎么计算输出特征图上每个点的值的:

p0是一个卷积核的中心点,pn是(3×3)卷积核的九个位置。可变形卷积就是在$x(p_0+p_n)$上再加个偏移量:

实际中,偏移量$\delta p_n$往往是小数,因此需要使用双线性插值计算这个添加了偏移量的点的数值。双线性插值如何计算,可参考RoI align中的相关公式。
那么这个偏移量是怎么来的?

对于特征图上的每个位置,都生成2kernel_wkernel_h个偏移,即2kernel_wkernel_h个channels的offset field,分别对应着kernel中每个位置的x,y偏移量。offset field的w和h为特征图的w和h。
Deformable RoI Pooling

先用标准的ROI pooling生成真正的pooled feature maps,然后利用一个fc layer生成normalized offsets,最后将其乘上ROI的size(pooling前)得到真正的offsets。使用真正的offsets对ROI pooling产生的bin进行偏移。
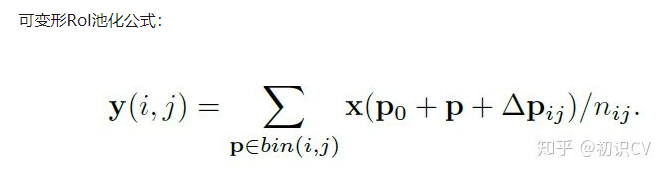
通过增加了卷积和池化的可变性,在参数量和推理时间没有显著增加的情况下,使得语义分割和目标检测的精度达到了一定的提升。
DCN V2(2018)
DCN V1的缺点
因为学习到的offsets不可控,因此可能会引入过多的context,对于positive样本来说,如果采样的特征包含了过多超出ROI的内容,那么结果将会受到影响和干扰。但是对于negative样本则恰恰相反,引入一些超出ROI的特征是有助于帮助网络判别这个区域是背景区域。
V2的改进主要在于
- 增加更多的Deformable Conv,V1中只有ResNet50的Conv5 stage(3层)中有Deformable Conv,V2中把Conv3-Conv5的3×3Conv(13层,4+6+3,作者说是12层,应该是笔误)都换成了Deformable Conv。
- 让Deformable Conv不仅能学习offset,还学习每个采样点的权重。
在DCN V2特征图上每个点的值的计算公式如下:
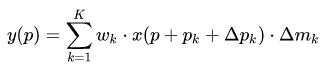
通过引入$\delta m_k$的权重,可以将不想要的采样点权重学成0。
同样的,Deformable RoI Pooling也可以引入权重。
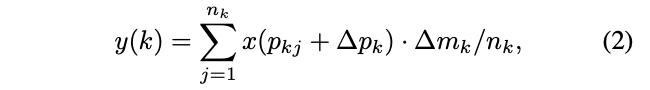
- RCNN mimicking
暂时不深入了解,可以参考:
https://blog.csdn.net/u014380165/article/details/88072737
https://zhuanlan.zhihu.com/p/90049906
https://www.zhihu.com/question/303900394/answer/540818451
FPN
NAS
ROI Align
双线性插值公式
Smooth L1 loss
Focal loss
OHEM
Soft-NMS
MMDetection
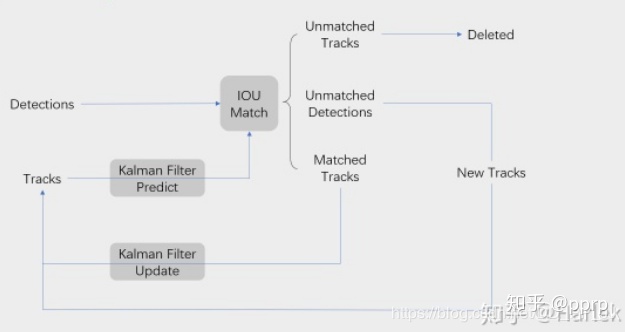
SORT
Simple Online and Realtime Tracking,于2016年被提出,主要由三部分组成:目标检测,卡尔曼滤波,匈牙利算法。
目标检测
目标检测在此不展开说明,作者使用的是Faster RCNN来获得bbox,也可替换为其他的检测算法。值得一提的是作者发现目标跟踪质量的好坏与检测算法的性能有很大的关系,通过使用先进的检测算法,跟踪结果的质量能够显著提升。
卡尔曼滤波
得到bbox后,我们是否就知道目标的准确位置了呢?从严格上来说,不是的。因为测量总是存在误差的,我们的通过目标检测得到的bbox会不可避免地带有噪声,导致bbox的位置不够精确。
卡尔曼滤波可以通过利用数学模型预测的值(根据1~t-1帧中目标的bbox,预测得到的第t帧的bbox)和测量得到的观测值(使用检测器检测得到的第t帧的bbox)进行数据融合(先预测t帧bbox,使用匈牙利算法与t帧检测得到的bbox进行匹配,再更新),找到“最优”(均方差最小)的估计值。
总之卡尔曼滤波是一种去噪技术,能够在目标检测的基础上,通过预测结果进行结合,得到更为准确的bbox。
匈牙利算法
匈牙利算法是一种数据关联算法,从本质上讲,跟踪算法要解决的就是数据关联问题,所以匈牙利算法的任务就是把t帧的bbox和t-1帧的bbox两两匹配(求解二分图的最大匹配,KM算法)。匈牙利算法依据的准则是“损失最小”,在SORT中利用预测得到的bbox和检测得到的bbox的交并比(IOU)来定义损失矩阵,例如损失矩阵$cost_{ij}$就表示前一帧第i个bbox(应该是根据前t-1帧预测得到的当前帧的第i个bbox?)与这一帧第j个bbox的IOU。
匹配有三种结果:
- Unmatched Tracks,这部分被认为是失配,Detection和Track无法匹配,如果失配持续了$T_{lost}$次,该目标ID将从图片中删除。
- Unmatched Detections, 这部分说明没有任意一个Track能匹配Detection, 所以要为这个detection分配一个新的track。
- Matched Track,这部分说明得到了匹配。
优点:
- 速度快
- 在没有遮挡的情况下准确度很高
缺点:
- 对物体遮挡几乎没有处理,导致id switch次数很多
- 有遮挡的情况下准确度很低
DeepSort
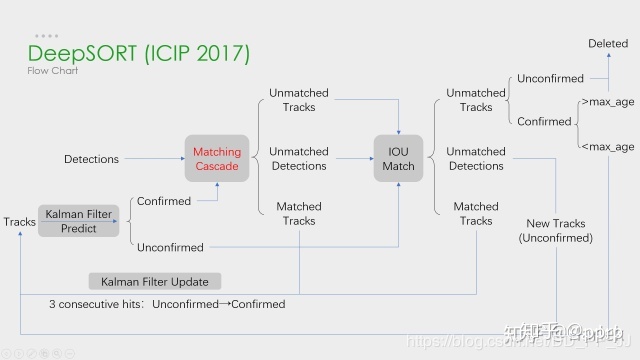
DeepSORT相比于SORT,最大的特点就是加入了外观信息,借用了ReID模型来提取特征,减少了id switch的次数。此外还加入了级联匹配机制和新轨迹的确认。
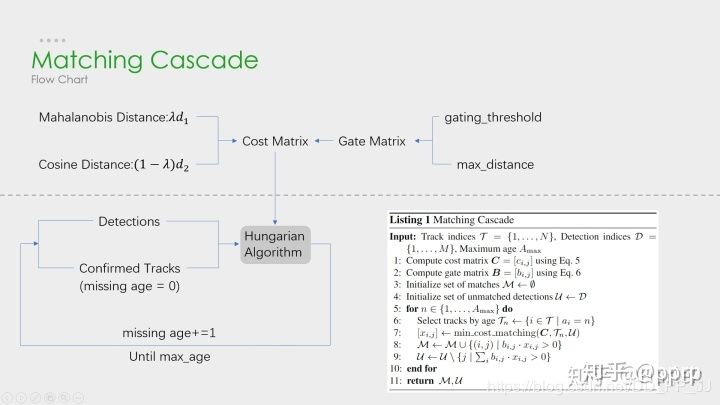
上图清晰地解释了如何进行级联匹配,上图由虚线划分为两部分:
上半部分中计算相似度矩阵的方法使用到了外观模型(ReID)和运动模型(马氏距离)来计算相似度,得到代价矩阵,另一个是门控矩阵,用于限制代价矩阵中过大的值(通过设定阈值及最大距离)。
下半部分中是级联匹配的数据关联步骤,匹配过程是一个循环(max age个迭代,默认为70),也就是从missing age=0~70的轨迹和detections进行匹配,没有丢失过的轨迹优先匹配,丢失较为久远的就靠后匹配。通过这部分处理,可以重新将被遮挡的目标找回,降低被遮挡然后再次出现的目标发生id switch的次数。
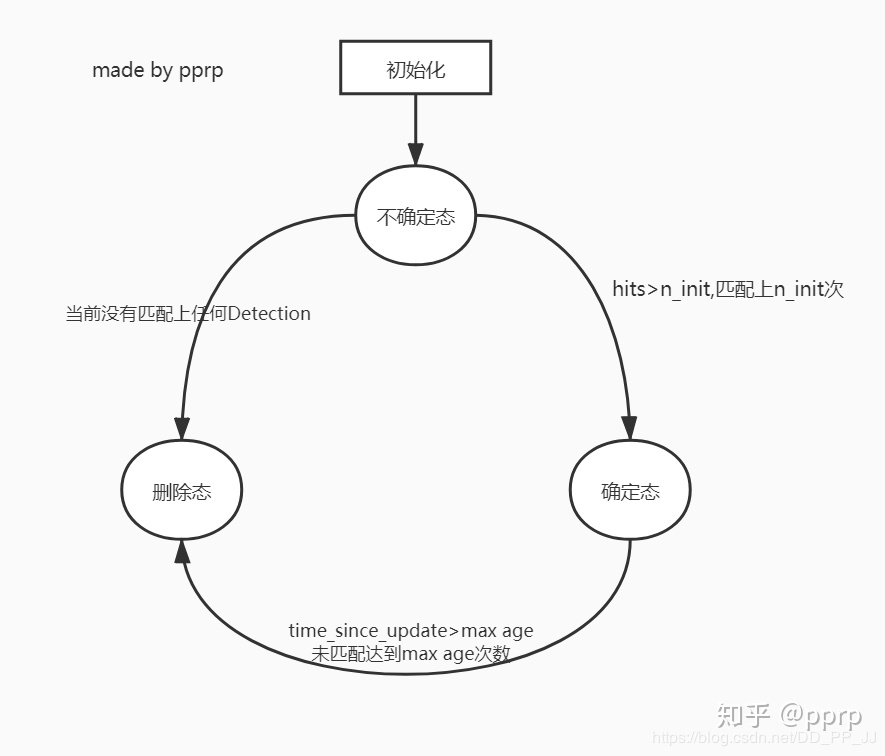
对于级联匹配失败的目标再进行IoU匹配,这部分于SORT中的几乎相同,但是在处理未匹配的轨迹,增加了确认(confirmed)状态和未确认(unconfirmed)状态。在轨迹为未确认状态和在确认状态下但未匹配次数大于max_age时,出现未匹配的情况,直接将该轨迹删除,否则继续保留该轨迹用于卡尔曼滤波。
对于一个处于未确认状态的轨迹,需要连续匹配n_init次后才能转换为确认状态。且未确认状态的轨迹只用于IoU匹配,确认状态的轨迹只用于级联匹配。
FairMOT
智力题
ac酱
更新于2020-04-07 下午
参考资料:
LeNet
AlexNet
ReLU
Dropout
VGGNet
GoogLenet
ResNet
DenseNet
MobileNet https://zhuanlan.zhihu.com/p/70703846 https://zhuanlan.zhihu.com/p/80041030
各种细节
后续备用 https://www.jianshu.com/p/7967556bcf75 https://blog.csdn.net/kuweicai/article/details/93926393 https://blog.csdn.net/weixin_30444105/article/details/98423768 https://www.zhihu.com/question/57194292 https://blog.csdn.net/GreatXiang888/article/details/99296607 https://blog.csdn.net/GreatXiang888/article/details/99310164 https://blog.csdn.net/GreatXiang888/article/details/99293507 https://blog.csdn.net/GreatXiang888/article/details/99221246 https://www.jianshu.com/p/a936b7bc54e3 https://www.jianshu.com/p/26a7dbc15246 https://www.jianshu.com/p/491c7bc0e87c https://www.jianshu.com/p/11bcb28ca0f0 https://zhuanlan.zhihu.com/p/22038289 https://tianchi.aliyun.com/forum/postDetail?postId=62131
https://www.zhihu.com/question/56024942/answer/498132341
inception v2+ https://my.oschina.net/u/876354/blog/1637819 https://zhuanlan.zhihu.com/p/73876718 https://zhuanlan.zhihu.com/p/73879583 https://zhuanlan.zhihu.com/p/73915627
视频 https://www.bilibili.com/video/BV1e7411R7DS?p=3 https://www.bilibili.com/video/BV1R7411a7dL?p=12 萌萌站起来,本地视频 https://www.bilibili.com/video/BV1iJ411V7pM https://www.bilibili.com/video/BV1iJ411V7A2 bilibili收藏夹 最新两个 https://www.bilibili.com/video/BV1S4411N7Nw?p=7 rcnn https://zhuanlan.zhihu.com/p/42643788 https://cloud.tencent.com/developer/article/1495383 spp https://zhuanlan.zhihu.com/p/27485018 https://blog.csdn.net/weixin_33672400/article/details/85943513 https://www.runoob.com/w3cnote/python-round-func-note.html fast rcnn https://zhuanlan.zhihu.com/p/43037119 https://zhuanlan.zhihu.com/p/42738847 faster rcnn https://zhuanlan.zhihu.com/p/43812909 https://zhuanlan.zhihu.com/p/44612080 https://zhuanlan.zhihu.com/p/31426458 https://zhuanlan.zhihu.com/p/42741973
https://zhuanlan.zhihu.com/p/72579976 https://www.zhihu.com/question/65587875 https://blog.csdn.net/Mr_health/article/details/84970776 https://zhuanlan.zhihu.com/p/61221686
cascade rcnn https://blog.csdn.net/u014380165/article/details/80602027 https://zhuanlan.zhihu.com/p/42553957 https://zhuanlan.zhihu.com/p/45036212 https://blog.csdn.net/Chunfengyanyulove/article/details/86414810 https://zhuanlan.zhihu.com/p/112828052 https://juejin.im/post/5b89377451882542d14da67e